Python笔记1.1(datetime、argparse、sys、overwrite、eval、json、os、zfill、endswith、traceback、深浅拷贝)
Python笔记2(函数参数、面向对象、装饰器、高级函数、捕获异常、dir) @TOC
14、with open() as file和open()参数详解
with open() as file: 是 Python 中用于打开文件的语法结构。
with和as是 Python 的关键字,用于创建一个上下文环境,确保在离开该环境时资源能够被正确关闭或释放。open()是一个内置函数,用于打开文件并返回一个文件对象。
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)open() 函数的各个参数的详细解释:
file:要打开的文件名(或文件路径)。可以是相对路径或绝对路径。mode(可选):打开文件的模式。它是一个字符串参数,默认值为'r'(只读模式)。常用的打开模式包括:'r':只读模式。文件从开头位置开始读取,默认模式。'w':写入模式。如果文件存在,则清空文件内容;如果文件不存在,则创建新文件进行写入。'x':独占创建模式。只写模式,用于创建新文件。如果文件已存在,则抛出FileExistsError异常。'a':追加模式。文件从末尾位置开始写入,如果文件不存在,则创建新文件。'b':二进制模式。以二进制形式读取或写入文件,用于处理非文本文件。't':文本模式(默认)。以文本形式读取或写入文件,用于处理文本文件。
buffering(可选):指定文件的缓冲策略。可以为整数值来指定缓冲区大小,或者使用-1(默认值)来选择默认的缓冲机制。encoding(可选):指定文件的编码格式。例如,'utf-8'、'latin-1'等。如果不指定该参数,在文本模式下将使用系统默认编码。errors(可选):指定编解码错误的处理方式。默认值为None,表示使用默认的错误处理机制。newline(可选):指定用于文本模式下换行符的转换方式。可以是None(默认值,保持系统默认),''(不进行转换),'\n'(将换行符转换为\n),'\r'(将换行符转换为\r)等。closefd(可选):定义当文件对象关闭时是否关闭与文件描述符相关的底层文件。默认值为True,表示关闭文件。opener(可选):用于自定义打开文件的底层实现的函数。
读写
# 1. 打开⽂件 f:file文件的缩写
f = open('test.txt', 'w')
# 2.⽂件写⼊
f.write('hello world')
# 3. 关闭⽂件
f.close()- writelines():写入的必须是列表类型。
- write():将一个字符串写入文件。
- readlines():可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素。
- readline():一次读取一行内容。
- read():读取文件中的所有内容,并返回一个字符串。
15、logging
- Logger:日志记录器,负责生成日志消息。
- Handler:处理器,负责将日志消息发送到不同的目的地(如控制台、文件等)。
- Formatter:格式化器,负责设置日志消息的格式。
- Filter:过滤器,负责过滤日志消息。
日志的等级
| 日志级别 | 使用场景 |
|---|---|
| DEBUG | 用于调试阶段,输出详细的调试信息,通常不会在生产环境中使用 |
| INFO | 用于输出程序运行的一般信息,例如程序启动、停止等 |
| WARNING | 用于输出警告信息,例如程序运行时出现了一些不严重的问题,但需要引起注意 |
| ERROR | 用于输出错误信息,例如程序运行时出现了一些严重的问题,需要及时处理 |
| CRITICAL | 用于输出严重的错误信息,例如程序崩溃、系统崩溃等,需要立即处理 |
logging.basicConfig(*kwargs)
| 参数名称 | 描述 |
|---|---|
| filename | 指定日志输出目标文件的文件名,指定该参数后日志信息就不会输出到控制台上 |
| filemode | 指定日志文件的打开模式,默认为’a’.需要注意的是,该选项要在filename被指定时才有效 |
| format | 指定日志格式字符串,即指定日志输出时所包含的字段信息以及它们的顺序 |
| datefmt | 指定日志记录中日期和时间的格式,该选项要在format中包含时间字段%(asctime)s时才有效 |
| level | 指定日志器的日志级别,小于该级别将不会输出 |
| stream | 指定日志输出目标stream,如sys.stdout、sys.stderr以及网络stream。需要说明的是,stream和filename不能同时提供,否则会引发 ValueError异常 |
| style | 指定format格式字符串的风格,可取值为’%‘、’{‘和’$‘,默认为’%’ |
format
| 字段/属性名称 | 使用格式 | 描述 |
|---|---|---|
| asctime | %(asctime)s | 日志事件发生的事时间 |
| levelname | %(levelname)s | 该日志记录的文字形式的日志级别(‘DEBUG’, ‘INFO’, ‘WARNING’, ‘ERROR’, ‘CRITICAL’) |
| message | %(message)s | 日志记录的文本内容,通过 msg % args计算得到的 |
| pathname | %(pathname)s | 调用日志记录函数的源码文件的全路径 |
| filename | %(filename)s | pathname的文件名部分,包含文件后缀 |
| module | %(module)s | filename的名称部分,不包含后缀 |
| lineno | %(lineno)d | 调用日志记录函数的源代码所在的行号 |
| funcName | %(funcName)s | 调用日志记录函数的函数名 |
TimedRotatingFileHandler
timed_rotating_handler = TimedRotatingFileHandler(
log_file_path,
when='midnight', # 每天午夜进行日志轮转
interval=1, # 每1天轮转一次(与 when='midnight' 配合表示每日轮转)
backupCount=7, # 最多保留 7 个备份文件(即保留最近7天的日志)
encoding='utf-8', # 使用 UTF-8 编码写入日志文件(确保中文等字符正确显示)
delay=0 # 不延迟文件创建(0=False,立即创建文件)
)参数详解
log_file_path- 日志文件的主路径(如:
app.log) - 轮转后的文件会自动添加日期后缀(如:
app.log.2023-10-27)
- 日志文件的主路径(如:
when='midnight'- 轮转时间点:每天午夜 00:00
- 其他常用值:
'S'- 秒'M'- 分钟'H'- 小时'D'- 天'W0'- W6:每周(0=周一,6=周日)
interval=1- 轮转间隔:与
when配合使用,表示每1个时间单位轮转一次 - 例如
when='H', interval=6表示每6小时轮转一次
- 轮转间隔:与
backupCount=7- 保留的备份文件数量:保留最近7个日志文件(不含当前活动文件)
- 当生成新日志文件时,最旧的日志文件会被自动删除
encoding='utf-8'- 文件编码:强烈建议设置为 UTF-8,特别是在需要记录中文或其他非ASCII字符时
delay=0- 延迟文件创建:0表示立即创建日志文件
- 如果设置为 True(或非零值),则直到第一次写入日志时才创建文件
避免日志多写,重写
logging.shutdown()
logging.shutdown 是 Python logging 模块中的一个函数,用于确保所有日志记录器和处理器在程序结束前正确关闭。这在多线程或多进程环境中尤为重要,因为日志记录器和处理器可能在不同的线程或进程中使用。
功能说明
- 确保所有日志消息被处理:logging.shutdown 会等待所有日志消息被处理完毕,确保没有未完成的日志记录任务。
- 关闭所有处理器:它会关闭所有已注册的处理器,特别是文件处理器,确保文件被正确关闭。
- 清理资源:释放与日志记录相关的资源,防止资源泄漏。
使用场景
- 多线程或多进程环境:在多线程或多进程环境中,确保所有线程或进程的日志记录任务完成后再关闭程序。
- 程序正常退出:在程序正常退出前调用 logging.shutdown,确保所有日志消息被正确记录。
- 异常处理:在捕获到异常后,确保日志记录器正确关闭,避免资源泄漏。
logging.getLogger()
logging.getLogger() 是 Python logging 模块中的一个方法,用于获取或创建一个日志记录器。如果不提供名称参数,默认会返回根日志记录器(root logger)。根日志记录器是所有日志记录器的顶级记录器,如果没有其他记录器处理日志消息,根日志记录器会处理这些消息。
功能说明
- 获取或创建日志记录器:如果指定名称的日志记录器已经存在,则返回该记录器;如果不存在,则创建一个新的记录器并返回。
- 根日志记录器:如果不提供名称参数,logging.getLogger() 会返回根日志记录器。
import logging
# 1、创建一个logger
logger = logging.getLogger('mylogger')
logger.setLevel(logging.DEBUG)
# 2、创建一个handler,用于写入日志文件
fh = logging.FileHandler('test.log')
fh.setLevel(logging.DEBUG)
# 再创建一个handler,用于输出到控制台
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
# 3、定义handler的输出格式(formatter)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
# 4、给handler添加formatter
fh.setFormatter(formatter)
ch.setFormatter(formatter)
# 5、给logger添加handler
logger.addHandler(fh)
logger.addHandler(ch)16、os、shutil、glob
os
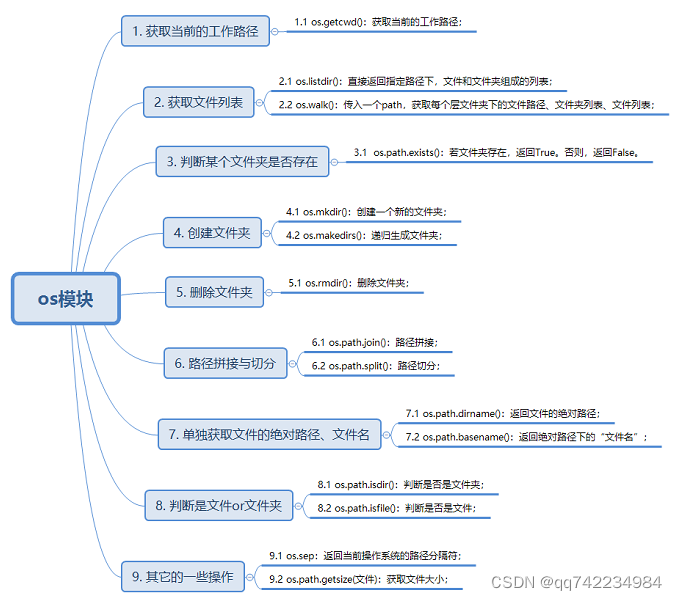 返回上一层路径 os.path.abspath(os.path.join(path, os.paridr))
返回上一层路径 os.path.abspath(os.path.join(path, os.paridr))
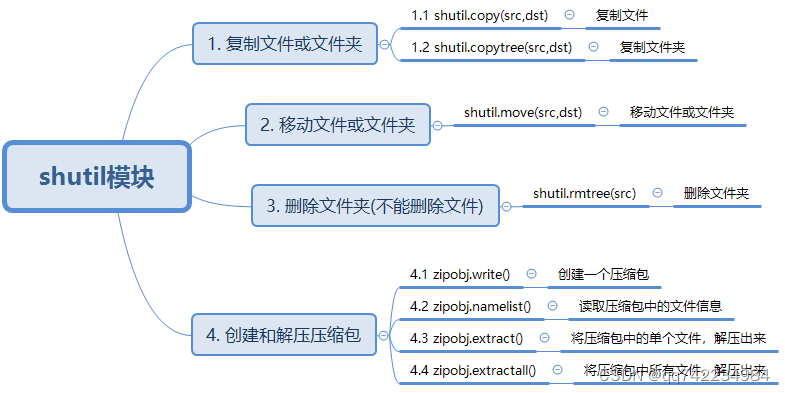
shutil
glob

查找指定的文件
想查找的文件名已知道,但目录在哪里不知道
# coding:utf-8
import glob
path = glob.os.path.join(glob.os.getcwd(), '*')
# 获取当前路径下所有内容
# 判断每个内容的类型(文件夹还是文件)
# 递归
final_result = []
def search(path, target):
result = glob.glob(path)
for data in result:
if glob.os.path.isdir(data):
_path = glob.os.path.join(data, '*')
search(_path, target)
else:
if target in data:
final_result.append(data)
return final_result
# /home/test1.py if test1 in /test1/abc.py
if __name__ == '__main__':
result = search(path, target='test1')
print(result)查找含有指定文件的内容
文件中包含某些关键字,但不知道文件名和所在路径
# coding:utf-8
import glob
path = glob.os.path.join(glob.os.getcwd(), '*')
# 获取当前路径下所有内容
# 判断每个内容的类型(文件夹还是文件)
# 递归
final_result = []
def search(path, target):
result = glob.glob(path)
for data in result:
if glob.os.path.isdir(data):
_path = glob.os.path.join(data, '*')
print('path is %s' % _path)
search(_path, target)
else:
f = open(data, 'r')
try:
content = f.read()
if target in content:
final_result.append(data)
except:
print('data read failed: %s' % data)
continue
finally:
f.close()
return final_result
if __name__ == '__main__':
result = search(path, target='dewei')
print(result)批量修改目录中的文件名称
知道文件名需要修改的字符串
# coding:utf-8
import glob
import shutil
def update_name(path):
result = glob.glob(path)
for index, data in enumerate(result):
if glob.os.path.isdir(data):
_path = glob.os.path.join(data, '*')
update_name(_path)
else:
path_list = glob.os.path.split(data)
# [/home/xxxx, name.txt]
name = path_list[-1]
new_name = '%s_%s' % (index, name) # '0_name.txt'
new_data = glob.os.path.join(path_list[0], new_name)
shutil.move(data, new_data)
if __name__ == '__main__':
path = glob.os.path.join(glob.os.getcwd(), '*')
update_name(path)批量查找并复制备份py脚本
import os
import shutil
import datetime
ymd = datetime.datetime.now().strftime("%Y%m%d")
# 工作目录路径
work_dir = os.getcwd()
# 递归遍历所有子目录,查找Python程序文件
for foldername, subfolders, filenames in os.walk(work_dir):
for filename in filenames:
if filename.endswith('.py'):
path_py = os.path.join(foldername, filename)
print(os.path.join(foldername, filename))
new_path = os.path.join(r"D:\beifen\py_{}\{}".format(ymd, path_py.split('Project\\')[1]))
if not os.path.exists(new_path):
os.makedirs(new_path)
if not os.path.exists(r"D:\beifen\py_{}\{}".format(ymd, path_py.split('Project')[1])):
shutil.copy(os.path.join(foldername, filename), new_path)
# exit()17、decode和encode
在 Python 中,字符串是以 Unicode 编码进行存储和操作的。Unicode 是一种字符集,为每个字符分配了唯一的数字编码,可以用于表示所有的字符集(包括 ASCII,拉丁文和其他字符集)。
在 Python 中,有两种主要的方法来将字符串转换为字节序列(编码)或将字节序列转换为字符串(解码):.encode() 和 .decode()。
.encode() 方法将字符串转换为字节序列,方法调用需要指定要使用的编码方式。例如,.encode('utf-8') 将字符串编码为以 UTF-8 编码的字节序列。返回一个 bytes 对象。
示例:
string = '这是一段中文字符'
encoded_string = string.encode('utf-8')
print(encoded_string)输出:b'\xe8\xbf\x99\xe6\x98\xaf\xe4\xb8\x80\xe6\xae\xb5\xe4\xb8\xad\xe6\x96\x87\xe5\xad\x97\xe7\xac\xa6'
.decode() 方法将字节序列转换为字符串,调用需要指定要使用的编码方式。例如,.decode('utf-8') 将以 UTF-8 编码的字节序列转换为字符串。返回一个字符串。
示例:
bytes_string = b'\xe8\xbf\x99\xe6\x98\xaf\xe4\xb8\x80\xe6\xae\xb5\xe4\xb8\xad\xe6\x96\x87\xe5\xad\x97\xe7\xac\xa6'
decoded_string = bytes_string.decode('utf-8')
print(decoded_string)输出:这是一段中文字符
需要注意的是,调用 .encode() 或 .decode() 时需要指定相应的编码方式。不同的编码方式可能在字符编码转换上存在差异,使用不当可能导致数据损坏或解码错误。
另外,Python 中的 .encode() 和 .decode() 方法只适用于 Python 字符串和字节序列之间的转换。如果要进行文件读写等操作,需要使用相应的文件读写方法。例如使用 open() 函数时,需要指定相应的模式。例如 open('file.txt', 'w', encoding='utf-8') 表示使用 UTF-8 编码打开文件以进行写操作。
18、pickle
1. 保存数据
使用 pickle.dump 方法将对象保存到文件中。
import pickle
with open('filename.pkl', 'wb') as file:
pickle.dump(obj, file)2. 加载数据
使用 pickle.load 方法从文件中加载对象。
import pickle
with open('filename.pkl', 'rb') as file:
obj = pickle.load(file)19、tqdm
tqdm 是一个在 Python 中常用的库,用于在循环中添加进度条,使长时间运行的任务更加直观。
- 进度条显示:可以在循环中显示进度条,支持多种自定义样式。
- 兼容性:适用于 for 循环、while 循环以及 iterable 对象。
- 多线程/多进程支持:可以在多线程或多进程中使用。
- 可配置:可以配置进度条的颜色、格式、更新频率等。
自定义进度条格式
from tqdm import tqdm
import time
for i in tqdm(range(100), desc="Processing", ncols=100, unit="item"):
time.sleep(0.01)多进程支持
from tqdm import tqdm
import multiprocessing as mp
def worker(x):
time.sleep(0.01)
return x * x
with mp.Pool(processes=4) as pool:
results = list(tqdm(pool.imap(worker, range(100)), total=100))