数据科学:Scipy、Scikit-Learn笔记 @TOC
一、Numpy
numpy.ndarray:n维数组
在numpy中以np.nan表示缺失值,它是一个浮点数。
np.random
np.random.randint
用于生成指定范围内的随机整数。以下是该函数的基本用法: 参数:
- low: 随机数的最小值(包含)。
- high: 随机数的最大值(不包含)。如果未提供,则默认为 low,且 low 为 0。
- size: 输出数组的形状。如果未提供,则返回单个整数。
- dtype: 返回数据的类型,默认为 int。
返回值:
- 单个整数或整数数组,具体取决于 size 参数。
np.random.uniform
用于生成服从均匀分布的随机数。均匀分布是指在指定区间内每个数值出现的概率相同。以下是该函数的基本用法和参数说明: 基本语法
numpy.random.uniform(low=0.0, high=1.0, size=None)参数说明
- low (float): 随机数生成的下限,默认为 0.0。
- high (float): 随机数生成的上限,默认为 1.0。生成的随机数严格小于 high。
- size (int or tuple of ints, optional): 输出数组的形状。如果为 None(默认),则返回单个浮点数。
返回值
- 如果 size 为 None,则返回一个浮点数。
- 如果 size 是整数或元组,则返回一个指定形状的 NumPy 数组,数组中的元素是从 [low, high) 区间内均匀分布的随机数。
np.random.rand(d0, d1, ..., dn)
- 生成 [0, 1) 范围内的均匀分布随机浮点数。
- 参数 d0, d1, ..., dn 指定输出数组的形状。
np.random.randn(d0, d1, ..., dn)
生成标准正态分布(均值为 0,标准差为 1)的随机浮点数。
- 参数 d0, d1, ..., dn 指定输出数组的形状。
np.random.choice(a, size=None, replace=True, p=None)
- 从给定的一维数组 a 中随机选择元素。
- size 指定输出数组的形状。
- replace 是否允许重复选择。
- p 是每个元素被选择的概率数组。
np.random.shuffle(x)
- 随机打乱数组 x 中的元素顺序。
- 注意:此方法会直接修改输入数组,不会返回新数组。
np.random.permutation(x)
- 返回数组 x 的随机排列。
- 如果 x 是整数,则返回从 0 到 x-1 的随机排列。
np.random.normal(loc=0.0, scale=1.0, size=None)
- 生成指定均值和标准差的正态分布随机浮点数。
- loc 是均值。 scale 是标准差。 size 指定输出数组的形状。
np.random.poisson(lam=1.0, size=None)
- 生成泊松分布的随机整数。
- lam 是泊松分布的参数(事件发生的平均次数)。
- size 指定输出数组的形状。
np.random.exponential(scale=1.0, size=None)
- 生成指数分布的随机浮点数。
- scale 是指数分布的尺度参数(1/λ,其中 λ 是速率参数)。
- size 指定输出数组的形状。
np.random.binomial(n, p, size=None)
- 生成二项分布的随机整数。
- n 是试验次数。
- p 是每次试验成功的概率。
- size 指定输出数组的形状。
np.random.multivariate_normal(mean, cov, size=None)
- 生成多元正态分布的随机浮点数。
- mean 是均值向量。
- cov 是协方差矩阵。\
- size 指定输出数组的形状。
np.random.seed(seed=None)
- 设置随机数生成器的种子,以确保结果可重复。
- seed 是种子值,可以是整数或其他哈希对象。
np.linalg
np.linalg.norm
用于计算向量或矩阵的范数。范数是一种衡量向量或矩阵大小的方法。以下是一些常见的范数类型及其计算方法:
常见范数类型
L1 范数(Manhattan 范数): 计算向量中所有元素的绝对值之和。 适用于稀疏向量,常用于特征选择和正则化。 L2 范数(Euclidean 范数): 计算向量中所有元素平方和的平方根。 最常用的范数,适用于大多数情况,特别是在优化问题中。 无穷范数(最大范数): 计算向量中绝对值最大的元素。 适用于需要关注最大值的情况。 Frobenius 范数: 对于矩阵,计算所有元素平方和的平方根。 适用于矩阵的大小度量,类似于向量的 L2 范数。 函数签名
numpy.linalg.norm(x, ord=None, axis=None, keepdims=False)参数:
- x: 输入数组,可以是向量或矩阵。
- ord: 范数类型,默认为 None(即 L2 范数)。
- axis: 计算范数的轴,可以是整数或元组。默认为 None,表示整个数组。
- keepdims: 如果为 True,则保留减少的维度;否则,减少的维度将被删除。默认为 False。
范数(Norm)是数学中用于衡量向量或矩阵大小的一种方法。它是一种函数,将向量或矩阵映射到非负实数,满足一定的性质。范数在许多领域都有广泛的应用,包括线性代数、数值分析、机器学习等。 范数的基本性质:非负性,齐次性,三角不等式
np.linalg.solve
用于求解线性方程组。 函数签名
numpy.linalg.solve(a, b)参数:
- a: 系数矩阵,形状为 (M, M) 的二维数组。
- b: 常数向量或矩阵,形状为 (M,) 或 (M, N) 的一维或二维数组。
返回值:
- x: 解向量或矩阵,形状与 b 相同。
np.linalg.eig
用于计算方阵的特征值和特征向量。这个函数可以返回一个包含特征值的数组和一个包含对应特征向量的矩阵。 函数签名
numpy.linalg.eig(a)参数:
- a: 输入的方阵,形状为 (N, N) 的二维数组。
返回值:
- w: 特征值数组,形状为 (N,) 的一维数组。
- v: 特征向量矩阵,形状为 (N, N) 的二维数组。每一列 v[:, i] 是对应特征值 w[i] 的特征向量。
np.linalg.svd
用于计算矩阵的奇异值分解(SVD)。SVD 是一种强大的矩阵分解方法,广泛应用于数据压缩、图像处理、推荐系统等领域。 函数签名
numpy.linalg.svd(a, full_matrices=True, compute_uv=True, hermitian=False)参数:
- a: 输入的矩阵,形状为 (M, N) 的二维数组。
- full_matrices: 布尔值,可选。如果为 True,则返回完整的 ( U ) 和 ( V^T ) 矩阵;如果为 False,则返回截断的 ( U ) 和 ( V^T ) 矩阵。默认为 True。
- compute_uv: 布尔值,可选。如果为 True,则返回 ( U )、( \Sigma ) 和 ( V^T );如果为 False,则只返回奇异值 ( \Sigma )。默认为 True。
- hermitian: 布尔值,可选。如果为 True,则假设输入矩阵是 Hermitian(对称或复共轭对称),这可以提高计算效率。默认为 False。
返回值:
- U: 左奇异向量矩阵,形状为 (M, M) 或 (M, K),取决于 full_matrices 参数。
- s: 奇异值数组,形状为 (K,),按降序排列。
- Vt: 右奇异向量矩阵的转置,形状为 (N, N) 或 (K, N),取决于 full_matrices 参数。
np.linalg.inv(a)
- 计算矩阵 a 的逆矩阵。
- a 必须是一个方阵(行数等于列数)。
np.linalg.det(a)
- 计算矩阵 a 的行列式。
- a 必须是一个方阵。
np.linalg.eig(a)
- 计算矩阵 a 的特征值和特征向量。
- a 必须是一个方阵。
- 返回值是一个包含特征值的数组和一个包含特征向量的矩阵。#### np.linalg.pinv(a, rcond=1e-15, hermitian=False) 计算矩阵 a 的 Moore-Penrose 伪逆。 rcond 是截断阈值,用于处理病态矩阵。
np.linalg.matrix_rank(M, tol=None, hermitian=False)
计算矩阵 M 的秩。 tol 是数值容差,用于判断矩阵的秩。 hermitian 指定矩阵是否为埃尔米特矩阵(复共轭对称矩阵)。
np.maximum
用于计算两个数组或标量之间的逐元素最大值。这个函数可以处理标量和数组,并且支持广播(broadcasting)。 函数签名
numpy.maximum(x1, x2, out=None, where=True, casting='same_kind', order='K', dtype=None, subok=True)参数:
- x1, x2: 输入数组或标量。如果两者都是数组,它们必须具有相同的形状或能够通过广播机制匹配。
- out: 可选,输出数组的形状和数据类型。
- where: 可选,布尔数组,指示哪些元素参与计算。
- casting, order, dtype, subok: 其他可选参数,用于控制计算的细节。
返回值:
- 一个新的数组,包含 x1 和 x2 逐元素的最大值。
np.where
用于根据条件选择数组中的元素。它可以用于多种场景,包括条件选择、多条件选择以及作为三元运算符的替代品。 函数签名
numpy.where(condition, [x, y])参数:
- condition: 一个布尔数组,表示条件。条件为 True 的位置将选择 x 中的元素,条件为 False 的位置将选择 y 中的元素。
- x: 可选,当条件为 True 时选择的数组或标量。
- y: 可选,当条件为 False 时选择的数组或标量。
返回值:
- 一个新的数组,根据条件从 x 和 y 中选择元素。如果只提供了 condition,则返回满足条件的索引。
np.linspace
用于生成在指定区间内均匀分布的数字序列。这个函数在数值计算、绘图和数据生成等场景中非常有用。 函数签名
numpy.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None, axis=0)参数:
- start: 序列的起始值。
- stop: 序列的结束值。如果 endpoint 为 True,则包含 stop 值;否则不包含。
- num: 生成的样本数量,默认为 50。
- endpoint: 布尔值,可选。如果为 True,则 stop 值包含在序列中;如果为 False,则 stop 值不包含在序列中。默认为 True。
- retstep: 布尔值,可选。如果为 True,则返回生成的数组和步长。默认为 False。
- dtype: 数据类型,可选。生成数组的数据类型。如果未指定,则根据 start 和 stop 的类型推断。
- axis: 整数,可选。在多维数组中,指定插入新轴的位置。默认为 0。
返回值:
- 一个包含均匀分布数字的 NumPy 数组。
- 如果 retstep 为 True,则返回一个元组 (array, step),其中 array 是生成的数组,step 是步长。
np.arange
用于生成在指定区间内等间隔的数字序列。这个函数类似于 Python 内置的 range 函数,但返回的是一个 NumPy 数组,而不是一个列表或范围对象。 函数签名
numpy.arange([start, ]stop, [step, ]dtype=None)参数:
- start: 序列的起始值,默认为 0。
- stop: 序列的结束值(不包含在序列中)。
- step: 序列的步长,默认为 1。
- dtype: 数据类型,可选。生成数组的数据类型。如果未指定,则根据 start、stop 和 step 的类型推断。
返回值:
- 一个包含等间隔数字的 NumPy 数组。
np.meshgrid
用于生成网格点坐标矩阵。这个函数在多维数据处理、绘图和科学计算中非常有用,尤其是在需要在二维或更高维度上进行操作时。 函数签名
numpy.meshgrid(*xi, indexing='xy', sparse=False, copy=True)参数:
- *xi: 一个或多个一维数组,表示每个维度上的坐标值。
- indexing: 字符串,可选。指定网格的索引顺序。可以是 'xy'(默认)或 'ij'。
- 'xy':笛卡尔坐标系,适用于二维数组。
- 'ij':矩阵索引顺序,适用于多维数组。
- sparse: 布尔值,可选。如果为 True,则返回稀疏网格,节省内存。默认为 False。
- copy: 布尔值,可选。如果为 True,则返回独立的数组副本。如果为 False,则返回视图。默认为 True。
返回值:
- 一个或多个二维(或多维)数组,表示网格点的坐标矩阵。
numpy.sort()
numpy.sort(a[, axis=-1, kind='quicksort', order=None]) Return a sorted copy of an array.- axis:排序沿数组的(轴)方向,0表示按列,1表示按行,None表示展开来排序,默认为-1,表示沿最后的轴排序。
- kind:排序的算法,提供了快排'quicksort'、混排'mergesort'、堆排'heapsort', 默认为‘quicksort'。
- order:排序的字段名,可指定字段排序,默认为None。
import numpy as np
dt = np.dtype([('name', 'S10'), ('age', np.int)])
a = np.array([("Mike", 21), ("Nancy", 25), ("Bob", 17), ("Jane", 27)], dtype=dt)
b = np.sort(a, order='name')
print(b)
# [(b'Bob', 17) (b'Jane', 27) (b'Mike', 21) (b'Nancy', 25)]
b = np.sort(a, order='age')
print(b)
# [(b'Bob', 17) (b'Mike', 21) (b'Nancy', 25) (b'Jane', 27)]numpy.argsort()
排序后,用元素的索引位置替代排序后的实际结果。
numpy.argsort(a[, axis=-1, kind='quicksort', order=None]) Returns the indices that would sort an array.参考
二、Pandas
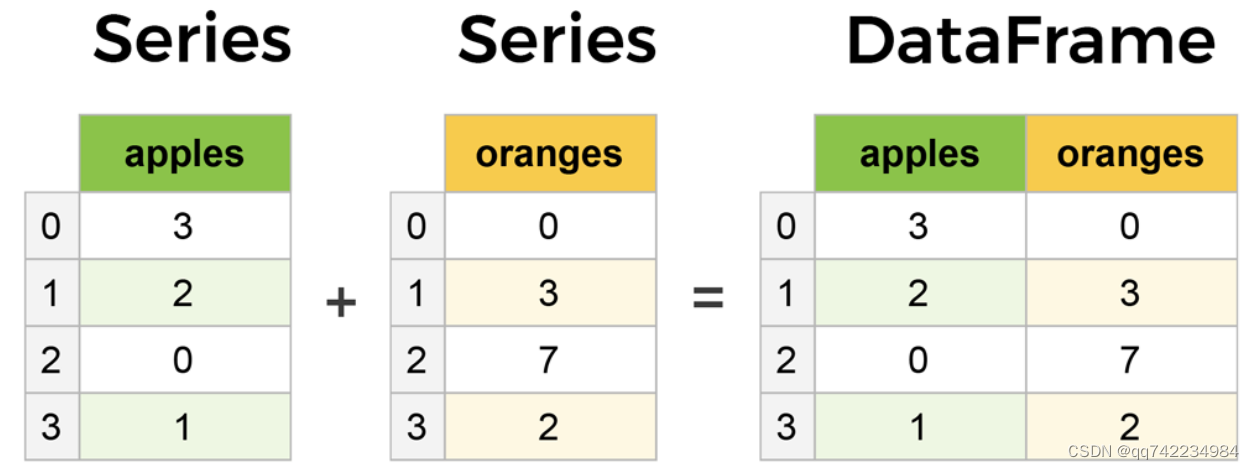
1.数据结构:Series、DataFrame
区别
- series,只是一个一维数据结构,它由index和value组成。
- dataframe,是一个二维结构,除了拥有index和value之外,还拥有column。
联系
- dataframe由多个series组成,无论是行还是列,单独拆分出来都是一个series。
2.date_range()函数
主要用于生成一个固定频率的时间索引
date_range(start=None, end=None, periods=None, freq=None, tz=None, normalize=False, name=None, inclusive=None, **kwargs)函数调用时至少要指定参数start、end、periods中的两个。
| 参数 | 数据类型 | 意义 |
|---|---|---|
| start | str or datetime-like, optional | 生成日期的左侧边界 |
| end | str or datetime-like, optional | 生成日期的右侧边界 |
| periods | integer, optional | 生成周期 |
| freq | str or DateOffset, default ‘D’ | 常见取值见下表 |
| tz | str or tzinfo, optional | 返回本地化的DatetimeIndex的时区名,例如’Asia/Hong_Kong’ |
| normalize | bool, default False | 生成日期之前,将开始/结束时间初始化为午夜 |
| name | str, default None | 产生的DatetimeIndex的名字 |
| closed | {None, ‘left’, ‘right’}, optional | 使区间相对于给定频率左闭合、右闭合、双向闭合(默认的None) |
| freq 常见取值 | 说明 |
|---|---|
| M | 月 |
| B | 工作日 |
| W | 星期天 |
| D | 天 |
| H | 小时 |
| T | 分钟 |
| S | 秒 |
| L | 毫秒 |
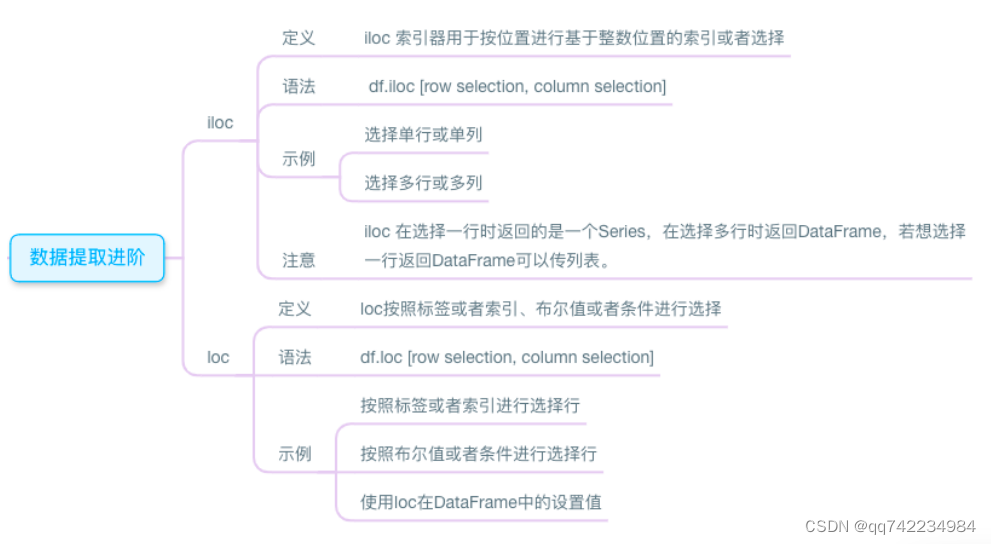
3.loc和iloc
loc表示location的意思;iloc中的loc意思相同,前面的i表示integer,所以它只接受整数作为参数。
iloc和loc区别联系
索引方式:
- iloc使用基于零的整数位置进行索引,通过行和列的整数位置来选择数据。
- loc使用标签进行索引,通过行和列的标签来选择数据。
索引对象类型:
- iloc使用整数位置作为索引,可以接受整数、整数切片或整数列表作为参数。
- loc使用标签作为索引,可以接受标签、标签切片或标签列表作为参数。
切片方式:
- iloc使用Python的切片语法,即左闭右开,例如[start:end]。
- loc使用Pandas的切片语法,即左闭右闭,例如[start:end]。
索引类型:
- iloc使用整数索引,无论数据框的索引类型是整数索引还是标签索引。
- loc使用标签索引,无论数据框的索引类型是整数索引还是标签索引。
参数省略:
- iloc可以省略行参数或列参数中的一个来选择所有行或所有列。
- loc可以省略行参数或列参数中的一个来选择所有行或所有列。
引用方式:
- iloc在选择数据时使用的是复制引用的方式,即返回的是数据的副本。
- loc在选择数据时使用的是原地引用的方式,即返回的是数据的视图。
4.dropna() 删除缺失值
df.dropna(
axis=0, #删除维度,0为行,1为列。默认为0。
how='any', #删除的判断条件。'any'代表这一行只要有一个空值就删除。'all'表示,这一行都是空值才删除。
thresh=None, # 例如,thresh=N,即,只要空值大于等于N的都删除,只保留空值小于N的行和列。
subset=None, # list,对特定的列的缺失值处理。
inplace=False # 布尔值,是否修改原数据。默认为False。
)5.判断重复值duplicated()和删除重复值drop_duplicates()
drop_duplicates(subset=None, keep='first', inplace=False, ignore_index=False)参数解析:
subset:列名或列名序列,对某些列来识别重复项,默认情况下使用所有列。
keep:可选值有first,last,False,默认为first,确定要保留哪些重复项。
first:删除除第一次出现的重复项,即保留第一次出现的重复项。 last:保留最后一次出现的重复项。 False:删除所有重复项。inplace:布尔值,默认为False,返回副本。如果为True,则直接在原始的Dataframe上进行删除。
ignore_index:布尔值,默认为False,如果为True,则生成的行索引将被标记为0、1、2、...、n-1。
6.sort_values()和sort_index()
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', ignore_index=False, key=None)参数说明:
- by:按照哪些列的数值进行排序。可以是一个字符串,也可以是一个由多个列名组成的列表或数组。
- axis:排序轴,0表示行(默认),1表示列。
- ascending:排序方式,True表示升序(默认),False表示降序。
- inplace:是否对原DataFrame对象进行修改。True表示修改原对象,False表示返回一个新的对象。
- kind:排序算法,可以是"quicksort"(默认)、"mergesort"或"heapsort"。
- na_position:缺失值的排列顺序,可以是"last"(默认)或"first"。
- ignore_index:是否重新生成索引,True表示生成新的连续索引,False表示保留原来的索引。
- key:排序时使用的函数,可以是一个函数、函数名或由多个函数组成的列表。
DataFrame.sort_index(axis=0, level=None, ascending=True, inplace=False, kind='quicksort', na_position='last', sort_remaining=True, ignore_index=False)7.DataFrame.prod()
返回值在请求的轴上的乘积
DataFrame.prod(axis=None, skipna=True, level=None, numeric_only=None, min_count=0, **kwargs)| 参数 | 值 | 描述 |
|---|---|---|
| axis | 要应用的函数的轴。 | |
| skipna | 布尔值,默认为True | 计算结果时排除NA/NULL值。 |
| level | Int或Level名称,默认为无 | 如果轴是多索引(分层),则沿特定级别计数,折叠为系列。 |
| numeric_only | 布尔,默认为无 | 包括浮点型、整型、布尔型列。如果没有,将尝试使用所有内容,然后仅使用数字数据。 |
| min_count | 整型,默认为0 | 执行操作所需的有效值数。如果少于 min_count 如果存在非NA值,则结果将为NA。 |
8.resample()
重采样是时间序列分析中处理时序数据的一项基本技术。它是关于将时间序列数据从一个频率转换到另一个频率,它可以更改数据的时间间隔,通过上采样增加粒度,或通过下采样减少粒度。 Pandas中的resample方法用于对时间序列数据进行重采样,可以将数据从一个时间频率转换为另一个时间频率。
df.resample(rule, how=None, axis=0, fill_method=None, closed=None, label=None, convention='start', kind=None, loffset=None, limit=None, base=0)参数说明:
- rule:重采样的规则,例如"5min"表示5分钟,"D"表示天。具体规则可以参考Pandas官方文档。
- how:对采样到的数据执行聚合操作的函数名或函数对象。例如"sum"、"mean"、"median"等。默认为None,表示不进行聚合操作。
- axis:指定重采样的轴,0表示行轴,1表示列轴。默认为0。
- fill_method:填充缺失值的方法,例如"ffill"、"bfill"等。默认为None,表示不填充缺失值。
- closed:在重采样过程中,区间闭合的位置,例如"left"、"right"等。默认为None,表示使用默认值。
- label:在重采样过程中,区间闭合位置的标签,例如"left"、"right"等。默认为None,表示使用默认值。
- convention:在重采样过程中,指定重采样区间的位置是左边界还是右边界。默认为"start",表示使用左边界。
- kind:在重采样过程中,指定返回的对象类型,例如"period"、"timestamp"等。默认为None,表示使用默认类型。
- loffset:在重采样过程中,为重采样的时间序列添加偏移量。
- limit:在重采样过程中,限制填充缺失值的连续次数。
- base:在重采样过程中,指定重采样区间的基准点。
import pandas as pd
import numpy as np
# 创建一个时间序列数据
rng = pd.date_range('1/1/2021', periods=100, freq='D')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
# 将数据按月份进行重采样,并计算每个月的平均值
ts.resample('M').mean()9.DataFrame.plot( )
使用pandas.DataFrame的plot方法绘制图像会按照数据的每一列绘制一条曲线,默认按照列columns的名称在适当的位置展示图例,比matplotlib绘制节省时间,且DataFrame格式的数据更规范,方便向量化及计算。
DataFrame.plot(x=None, y=None, kind='line', ax=None, subplots=False,
sharex=None, sharey=False, layout=None, figsize=None,
use_index=True, title=None, grid=None, legend=True,
style=None, logx=False, logy=False, loglog=False,
xticks=None, yticks=None, xlim=None, ylim=None, rot=None,
fontsize=None, colormap=None, position=0.5, table=False, yerr=None,
xerr=None, stacked=True/False, sort_columns=False,
secondary_y=False, mark_right=True, **kwds)x和y:表示标签或者位置,用来指定显示的索引,默认为None
kind:表示绘图的类型,默认为line,折线图
line:折线图 bar/barh:柱状图(条形图),纵向/横向 pie:饼状图 hist:直方图(数值频率分布) box:箱型图 kde:密度图,主要对柱状图添加Kernel 概率密度线 area:区域图(面积图) scatter:散点图 hexbin:蜂巢图ax:子图,可以理解成第二坐标轴,默认None
subplots:是否对列分别作子图,默认False
sharex:共享x轴刻度、标签。如果ax为None,则默认为True,如果传入ax,则默认为False
sharey:共享y轴刻度、标签
layout:子图的行列布局,(rows, columns)
figsize:图形尺寸大小,(width, height)
use_index:用索引做x轴,默认True
title:图形的标题
grid:图形是否有网格,默认None
legend:子图的图例
style:对每列折线图设置线的类型,list or dict
xticks:设置x轴刻度值,序列形式(比如列表)
yticks
xlim:设置坐标轴的范围。数值,列表或元组(区间范围)
ylim
rot:轴标签(轴刻度)的显示旋转度数,默认None
fontsize : int, default None#设置轴刻度的字体大小
colormap:设置图的区域颜色
colorbar:柱子颜色
position:柱形图的对齐方式,取值范围[0,1],默认0.5(中间对齐)
table:图下添加表,默认False。若为True,则使用DataFrame中的数据绘制表格
yerr:误差线
xerr
stacked:是否堆积,在折线图和柱状图中默认为False,在区域图中默认为True
sort_columns:对列名称进行排序,默认为False
secondary_y:设置第二个y轴(右辅助y轴),默认为False
mark_right : 当使用secondary_y轴时,在图例中自动用“(right)”标记列标签 ,默认True
x_compat:适配x轴刻度显示,默认为False。设置True可优化时间刻度的显示
10.cumsum()
cumsum函数是pandas的累加函数,用来求列的累加值。
DataFrame.cumsum(axis=None, skipna=True, args, kwargs)- axis:
- skipna:排除NA /空值。如果整个行/列均为NA,则结果为NA
11.isna()和isnull()
# 分别统计每一列的缺失值比例和每一行的缺失值比例
df.isna().mean() # 默认mean的axis参数为0,按照行方向计算列的均值。
df.isna().mean(axis=1)
# 如果想要统计每列包含的缺失值个数,只需把mean替换为sum即可。
# 如果想知道缺失的行或列具体实哪一些,可以如下操作:
df[df.isna().sum(1) >= 2]# 判断有空值的列
df.isnull().any()
# 显示出有空值列的列名的列表
df.columns[iris.isnull().any()].tolist()12.idxmax()和idxmin()
返回一列最大值所在行的行索引df.idxmax(),默认参数为0;若参数设置为1,则为一行最大值所在列的列索引df.idxmax(1)。(取最小值为df.idxmin())
13.io读取与存储
read_csv()
pandas.read_csv(filepath_or_buffer, sep=', ', delimiter=None, header='infer', names=None,
index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None,
engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False,
skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False,
skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False,
date_parser=None, dayfirst=False, iterator=False, chunksize=None, compression='infer',
thousands=None, decimal=b'.', lineterminator=None, quotechar='"', quoting=0, escapechar=None,
comment=None, encoding=None, dialect=None, tupleize_cols=None, error_bad_lines=True,
warn_bad_lines=True, skipfooter=0, skip_footer=0, doublequote=True, delim_whitespace=False,
as_recarray=None, compact_ints=None, use_unsigned=None, low_memory=True, buffer_lines=None,
memory_map=False, float_precision=None常用参数:
filepath_or_buffer:字符串,或者任何对象的read()方法。这个字符串可以是URL,有效的URL方案包括http、ftp、s3和文件。
sep : str, default ‘,’。指定分隔符。如果不指定参数,则会尝试使用逗号分隔。分隔符长于一个字符并且不是‘\s+’,将使用python的语法分析器。并且忽略数据中的逗号。正则表达式例子:’\r\t’。
delimiter : str, default None。定界符,备选分隔符(如果指定该参数,则sep参数失效)
delim_whitespace : boolean, default False. 指定空格是否作为分隔符使用,等效于设定sep=’\s+’。如果这个参数设定为Ture那么delimiter 参数失效。在版本0.18.1支持
header : int or list of ints, default ‘infer’。指定行数用来作为列名,数据开始行数。如果文件中没有列名,则默认为0,否则设置为None。如果明确设定header=0 就会替换掉原来存在列名。header参数可以是一个list例如:[0,1,3],这个list表示将文件中的这些行作为列标题(意味着每一列有多个标题),介于中间的行将被忽略掉。
注意:如果skip_blank_lines=True 那么header参数忽略注释行和空行,所以header=0表示第一行数据而不是文件的第一行。names : array-like, default None。用于结果的列名列表,如果数据文件中没有列标题行,就需要执行header=None。默认列表中不能出现重复,除非设定参数mangle_dupe_cols=True。
index_col : int or sequence or False, default None。用作行索引的列编号或者列名,如果给定一个序列则有多个行索引。如果文件不规则,行尾有分隔符,则可以设定index_col=False 保证pandas用第一列作为行索引。
usecols : array-like, default None。返回一个数据子集,该列表中的值必须可以对应到文件中的位置(数字可以对应到指定的列)或者是字符传为文件中的列名。例如:usecols有效参数可能是[0,1,2]或者是 [‘foo’, ‘bar’, ‘baz’]。使用这个参数可以加快加载速度并降低内存消耗。
squeeze : boolean, default False。如果文件值包含一列,则返回一个Series。
prefix : str, default None。在没有列标题时,给列添加前缀。例如:添加‘X’ 成为 X0, X1, …
mangle_dupe_cols : boolean, default True。重复的列,将‘X’…’X’表示为‘X.0’…’X.N’。如果设定为false则会将所有重名列覆盖。
dtype : Type name or dict of column -> type, default None 每列数据的数据类型。例如
engine : {‘c’, ‘python’}, optional。使用的分析引擎。可以选择C或者是python。C引擎快但是Python引擎功能更加完备。
converters : dict, default None。列转换函数的字典。key可以是列名或者列的序号。
skipinitialspace : boolean, default False。忽略分隔符后的空白(默认为False,即不忽略).
skiprows : list-like or integer, default None。需要忽略的行数(从文件开始处算起),或需要跳过的行号列表(从0开始)。
skipfooter : int, default 0。从文件尾部开始忽略。 (c引擎不支持)
nrows : int, default None。需要读取的行数(从文件头开始算起)。
na_values : scalar, str, list-like, or dict, default None。一组用于替换NA/NaN的值。如果传参,需要制定特定列的空值。默认为‘1.#IND’, ‘1.#QNAN’, ‘N/A’, ‘NA’, ‘NULL’, ‘NaN’, ‘nan’`.
keep_default_na : bool, default True。如果指定na_values参数,并且keep_default_na=False,那么默认的NaN将被覆盖,否则添加。
na_filter : boolean, default True。是否检查丢失值(空字符串或者是空值)。对于大文件来说数据集中没有空值,设定na_filter=False可以提升读取速度。
verbose : boolean, default False。是否打印各种解析器的输出信息,例如:“非数值列中缺失值的数量”等。
skip_blank_lines : boolean, default True。如果为True,则跳过空行;否则记为NaN。
date_parser : function, default None。用于解析日期的函数,默认使用dateutil.parser.parser来做转换。
iterator : boolean, default False。返回一个TextFileReader 对象,以便逐块处理文件。
chunksize : int, default None。文件块的大小, See IO Tools docs for more informationon iterator and chunksize.
compression : {‘infer’, ‘gzip’, ‘bz2’, ‘zip’, ‘xz’, None}, default ‘infer’。直接使用磁盘上的压缩文件。如果使用infer参数,则使用 gzip, bz2, zip或者解压文件名中以‘.gz’, ‘.bz2’, ‘.zip’, or ‘xz’这些为后缀的文件,否则不解压。如果使用zip,那么ZIP包中国必须只包含一个文件。设置为None则不解压。版本0.18.1版本支持zip和xz解压
thousands : str, default None。千分位分割符,如“,”或者“.”
decimal : str, default ‘.’。字符中的小数点 (例如:欧洲数据使用’,‘).
lineterminator : str (length 1), default None。行分割符,只在C解析器下使用。
encoding : str, default None。指定字符集类型,通常指定为’utf-8’. List of Python standard encodings。
to_csv()
DataFrame.to_csv(path_or_buf=None, sep=', ', na_rep='', float_format=None, columns=None,
header=True, index=True, index_label=None, mode='w', encoding=None, compression=None,
quoting=None, quotechar='"', line_terminator='\n', chunksize=None, tupleize_cols=None,
date_format=None, doublequote=True, escapechar=None, decimal='.')- path_or_buf:字符串或文件句柄,默认无文件。路径或对象,如果没有提供,结果将返回为字符串。
- sep : character, default ‘,’ Field delimiter for the output file. 默认字符 ‘ ,’ 输出文件的字段分隔符。
- columns : sequence, optional Columns to write。可选列写入
- header : boolean or list of string, default True:字符串或布尔列表,默认为true。写出列名。如果给定字符串列表,则假定为列名的别名。
- index : boolean, default True:布尔值,默认为Ture。写入行名称(索引)
- index_label : string or sequence, or False, default None:字符串或序列,或False,默认为None。如果需要,可以使用索引列的列标签。如果没有给出,且标题和索引为True,则使用索引名称。如果数据文件使用多索引,则应该使用这个序列。如果值为False,不打印索引字段。
- mode : str:模式:值为‘str’,字符串。Python写模式,默认“w”
- encoding : string, optional:编码:字符串,可选。表示在输出文件中使用的编码的字符串,Python 2上默认为“ASCII”和Python 3上默认为“UTF-8”。
- compression : string, optional:字符串,可选项。表示在输出文件中使用的压缩的字符串,允许值为“gzip”、“bz2”、“xz”,仅在第一个参数是文件名时使用。
- date_format : string, default None:字符串,默认为None。字符串对象转换为日期时间对象。
read_excel()
read_excel(io, sheetname=0, header=0, skiprows=None, skip_footer=0, index_col=None,names=None,
parse_cols=None, parse_dates=False,date_parser=None,na_values=None,thousands=None, convert_float=True,
has_index_names=None, converters=None,dtype=None, true_values=None, false_values=None, engine=None, squeeze=False, **kwds)常用参数解析:
io : string, path object ; excel 路径。
sheetname : string, int, mixed list of strings/ints, or None, default 0
返回多表使用sheetname=[0,1],若sheetname=None是返回全表 注意:int/string 返回的是dataframe,而none和list返回的是dict of dataframeheader : int, list of ints, default 0 指定列名行,默认0,即取第一行,数据为列名行以下的数据;若数据不含列名,则设定 header = None
skiprows : list-like,Rows to skip at the beginning,省略指定行数的数据。
skip_footer : int,default 0, 省略从尾部数的int行数据。
index_col : int, list of ints, default None指定列为索引列,也可以使用u”strings”
names : array-like, default None, 指定列的名字。
usecols:指定要读取的列范围,可以是列名称、列索引或一个包含列名称/索引的列表。
to_excel()
to_excel(self, excel_writer, sheet_name='Sheet1', na_rep='', float_format=None,
columns=None, header=True, index=True, index_label=None,startrow=0, startcol=0,
engine=None, merge_cells=True, encoding=None,inf_rep='inf', verbose=True, freeze_panes=None)excel_writer:指定要写入的 Excel 文件的路径或文件对象。
sheet_name:指定要写入的工作表名称。
index:指定是否写入行索引,默认为 True。
header:指定是否写入表头,默认为 True。
startrow:指定写入数据的起始行号。
startcol:指定写入数据的起始列号。
na_rep:指定缺失值的表示方式。
columns=None:指定输出某些列 列 = [“名称”, “数字”]
encoding=None:指定编码,常用 utf-8
float_format=None:浮点数保存的格式,默认保存为字符串
float_format=’%.2f’ # 保存为浮点数,保留2位小数engine=None:保存格式。
ExcelWriter()
有时一个excel内会有多个sheet。但是将两组数据通过to_excel函数先后保存到一个excel内会发现只有后一组保存的数据,因为前一组的数据被后写入的数据覆盖了。
df1.to_excel('xxx.xlsx',sheet_name='df1')
df2.to_excel('xxx.xlsx',sheet_name='df2')使用pd.ExcelWriter建立一个writer,然后,将df1,df2都使用to_excel(writer, sheet名),最后一次性将这些数据保存,并关闭writer就完成了。
writer = pd.ExcelWriter('xxx.xlsx')
df1.to_excel(writer,sheet_name="df1")
df2.to_excel(writer,sheet_name="df2")
writer.save()
writer.close()这样会覆盖我们原有的excel数据,如果不想覆盖,可以:
writer = pd.ExcelWriter('保存.xlsx') # 如果不存在,会自动创建excel
df = pd.read_excel("xxx.xlsx", sheet_name=xxx)
......
df_res.to_excel(writer, sheet_name=xxx, index=False)# 一次写入多个sheet
with pd.ExcelWriter('writer.xlsx') as writer:
data.to_excel(writer,sheet_name='a')
data.to_excel(writer,sheet_name='b')
data.to_excel(writer,sheet_name='c')
# 追加新sheet
with pd.ExcelWriter('writer.xlsx',mode='a',engine='openpyxl') as writer:
data2.to_excel(writer,sheet_name='d')
# 测试excel追加数据至sheet
with pd.ExcelWriter('writer.xlsx',mode='a',engine='openpyxl') as writer:
data.to_excel(writer,sheet_name='d')14.describe()
DataFrame.describe(percentiles=None, include=None, exclude=None)- percentiles:设置输出的百分位数,默认为[.25,.50,.75],返回第25,50,75百分位数。
- include:包含哪类数据。默认只包含连续值,不包含离散值;include = ‘all’ 设置全部类型。
- exclude:描述 DataFrame 时要排除的数据类型列表。默认为无
对于对象类型数据(例如字符串或时间戳),则结果的指数将包括count,unique, top,和freq。top标识最常见的值。freq标识最常见的值的出现频次。时间戳还包括first和last指标。如果多个对象值具有最高计数,那么将从具有最高计数的那些中任意选择count和top结果。
15.数据合并concat、merge和join
concat()
可以沿着一条轴将多个对象进行堆叠,其使用方式类似数据库中的数据表合并。
pandas.concat(objs, axis=0, join=’outer’, join_axes=None, ignore_index=False, keys=None, levels=None, verify_integrity=False, sort=None, copy=True)| 参数 | 作用 |
|---|---|
| axis | 默认为0,0为行拼接,1为列拼接,意为沿着连接的轴。 |
| join | {‘inner’,‘outer’},默认为“outer”。如何处理其他轴上的索引。outer为并集和inner为交集。 |
| ignore_index | 接收布尔值,默认为False。如果设置为True,则表示清除现有索引并重置索引值 |
| keys | 接收序列,表示添加最外层索引 |
| levels | 用于构建MultiIndex的特定级别(唯一值) |
| names | 设置了keys和level参数后,用于创建分层级别的名称 |
| verify_integerity | 检查新的连接轴是否包含重复项。接收布尔值,当设置为True时,如果有重复的轴将会抛出错误,默认为False |
merge
merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False)参数说明:
- left:参与合并的左侧DataFrame
- right:参与合并的右侧DataFrame
- how:{inner、outer、left、right}default为inner为交集。
- on:用于连接的列名。该列名就像连接的两张表中共同的特征。类似按键合并多表。如果未制定,且其他连接键也没用制定,则以left和right列名的交集为连接键,也就是inner连接。
- left_on:左侧DataFrame中用作连接键的列
- right_on:右则DataFrame中用作连接键的列
- left_index:使用左则DataFrame中的行索引做为连接键
- right_index:使用右则DataFrame中的行索引做为连接键
- sort:默认为True,将合并的数据进行排序。在大多数情况下设置为False可以提高性能
- suffixes:字符串值组成的元组,用于指定当左右DataFrame存在相同列名时在列名后面附加的后缀名称,默认为(‘_x’,‘_y’)。如果两个DataFrame对象都有“Data”,则结果中就会出现“Data_x”和"Data_y“
join()
能够通过索引或指定列来连接多个DataFrame对象
join(other,on = None,how =‘left’,lsuffix =‘’,rsuffix =‘’,sort = False )16.groupby
groupby 函数是 Pandas 库中 DataFrame 和 Series 对象的一个方法,它允许你对这些对象中的数据进行分组和聚合。 对于 DataFrame 对象,groupby 函数的语法如下:
DataFrame.groupby(by=None, axis=0, level=None, as_index=True,
sort=True, group_keys=True, squeeze=False,
observed=False, dropna=True)其中,各个参数的含义如下:
- by:用于分组的列名或函数。可以是一个列名、一个函数、一个列表或一个字典。按多个字段分组时传入列表。
- axis:分组轴。如果axis=0(默认值),则沿着行方向分组;如果 axis=1,则沿着列方向分组。
- level:当DataFrame的索引为多重索引时,level参数指定用于分组的索引,可以传入多重索引中索引的下标(0,1...)或索引名,多个用列表传入。
- as_index:分组结果默认将分组列的值作为索引,如果按单列分组,结果默认是单索引,如果按多列分组,结果默认是多重索引。是否将分组键作为索引返回。如果as_index=True(默认值),则返回一个带有分组键作为索引的对象;否则返回一个不带索引的对象。
- sort:是否对分组键进行排序。如果 sort=True(默认值),则对分组键进行排序;否则不排序。
- group_keys:是否在结果中包含分组键。如果 group_keys=True(默认值),则在结果中包含分组键;否则不包含。
- dropna:是否删除包含缺失值的行。如果dropna=True(默认值),则删除包含缺失值的行;否则保留。
groupby()分组得到的是一个DataFrameGroupBy对象,直接打印DataFrameGroupBy对象只能看到它的内存地址,看不到内部的结构。
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x000007C4E22D3498>DataFrameGroupBy是一个可迭代对象,可以转换成list打印,也可以直接遍历打印出来。遍历出来的是一个个元组,每个元组对应一个分组,元组的第一个元素与分组列里的值对应,元组的第二个元素是分到当前小组的数据,是一个DataFrame。
DataFrameGroupBy对象的内部结构为:[(分组名1, 子DataFrame1), (分组名2, 子DataFrame2), ...],相当于groupby()将DataFrame按字段值分成了多个小的DataFrame,然后将字段值和小的DataFrame用元组的方式保存在DataFrameGroupBy对象中。
分组对象的groups属性可以返回分组信息,结果是一个形似字典的对象,由分组名和此分组数据在原DataFrame中的行索引组成。
借用groups可以提取出所有分组的分组名,分组对象的get_group()方法可以返回指定分组名的子DataFrame。
aggregate、apply、transform
DataFrame.agg
DataFrame.agg(func=None, axis=0, *args, **kwargs);针对特定的轴进行一个或者多个聚合操作。
- func:函数,可以为str, list或者dict类型。可接受的组合包括:函数,字符串形式的函数名,函数或函数名列表(如[np.sum, 'mean']),轴标签字典->函数,函数名或此类的列表。
count() – Number of non-null observations
sum() – Sum of values
mean() – Mean of values
median() – Arithmetic median of values
min() – Minimum
max() – Maximum
mode() – Mode
std() – Standard deviation
var() – Variance- axis:0 or ‘index’, 1 or ‘columns’,默认为0。如果0或'index',对每一列应用函数;如果1或'columns',应用函数到每一行。
DataFrame.apply
DataFrame.apply(func, axis=0, raw=False, result_type=None, args=(), **kwargs);沿着dataframe的轴进行操作。
- func:同agg
- axis:同agg
- raw:布尔型,默认为False。确定是否将行或列作为Series或ndarray对象传递。如果设置为False,将每一行或每一列作为series传递给函数;如果设置为True,传递的函数将接收ndarray对象。如果只是应用NumPy缩减函数,可以设置为Ture,会获得更好的性能.
DataFrame.transformDataFrame.transform(func, axis=0, *args, **kwargs);调用func函数生成带有转换值的DataFrame,生成的DataFrame将具有与self相同的轴长。
17.query方法
在pandas中,支持把字符串形式的查询表达式传入query方法来查询数据,其表达式的执行结果必须返回布尔列表。在进行复杂索引时,由于这种检索方式无需像普通方法一样重复使用DataFrame的名字来引用列名,一般而言会使代码长度在不降低可读性的前提下有所减少。
示例
# 选出col0在30到80之间的行中col3与col1之差为奇数的行,
# 或者col2大于50中的行col3超过col1均值的行
c11 = df["col 0"].between(30, 80)
c12 = (df["col 3"] - df["col 1"]) % 2 ==1
c21 = df["col 2"] > 50
c22 = df["col 3"] > df["col 1"].mean()
df.loc[(c11 & c12) | (c21 & c22)]
# dataframe保留两位小数
df = df.round(2)
# 写入WPD
def WriteTXT(data: pd.DataFrame, savepath: str):
with open(savepath, "w", 65536, 'utf-8') as file:
h1 = "// matfile"
file.write(h1.strip() + "\n")
for key, items in data.iterrows():
items_l = list(items)
line = str()
for i in range(len(items_l)):
if i == 0:
line += items_l[i]
line += ' '
elif i == 1:
line += str(items_l[i])
line += ' '
elif i == 2:
line += items_l[i]
line += ' '
elif i == len(items_l) - 1:
line += str("%.6f" % items_l[i])
else:
line += str("%.6f" % items_l[i])
line += ' '
file.write(line.strip() + "\n")
file.write(h1.strip() + "\n")参考
1.pd.set_option()参数详解 2.Python的reshape的用法:reshape(1,-1)、reshape(-1,1) 3.https://github.com/datawhalechina/joyful-pandas 4.https://github.com/datawhalechina/powerful-numpy 5.Pandas实践