@[TOC](Transformer;Hugging Face之transformers库、datasets库详解;Modelscope)
Transformer
Transformer 是一种深度学习模型,它主要用于处理序列数据,如自然语言处理任务中的文本翻译、情感分析等。Transformer 模型由 Google 在 2017 年的论文《Attention is All You Need》中首次提出,其核心创新在于自注意力机制(Self-Attention Mechanism),这使得模型能够并行处理输入序列的所有元素,从而显著提高了训练效率和性能。
Transformer 的主要组成部分
编码器(Encoder)
编码器由多个相同的层堆叠而成,每一层包含两个子层:
- 多头自注意力机制(Multi-Head Self-Attention):允许模型在不同的表示子空间中关注输入的不同部分。
- 前馈神经网络(Feed-Forward Neural Network):一个简单的全连接层,对每个位置的特征进行变换。
解码器(Decoder)
解码器也由多个相同的层堆叠而成,每一层包含三个子层:
- 多头自注意力机制(Multi-Head Self-Attention):与编码器类似,但会应用掩码(Masking)以防止当前位置关注到未来的位置。
- 多头注意力机制(Multi-Head Attention):将编码器的输出作为键(Key)和值(Value),当前解码器的输出作为查询(Query),实现编码器和解码器之间的交互。
- 前馈神经网络(Feed-Forward Neural Network):与编码器中的前馈神经网络相同。
位置编码(Positional Encoding)
由于 Transformer 模型本身不包含任何关于输入序列顺序的信息,因此需要添加位置编码来引入位置信息。位置编码通常采用正弦和余弦函数的形式。
残差连接与层归一化(Residual Connections & Layer Normalization)
每个子层后面都跟着一个残差连接(Residual Connection),然后是层归一化(Layer Normalization)。这有助于缓解梯度消失问题,并加速训练过程。
自注意力机制(Self-Attention Mechanism)
自注意力机制是 Transformer 模型的核心,它允许模型在处理某个位置的输入时,考虑其他所有位置的输入。具体步骤如下:
- 线性变换:将输入向量分别通过三个不同的线性变换(权重矩阵),得到查询(Query)、键(Key)和值(Value)向量。
- 计算注意力分数:通过查询和键的点积计算注意力分数,然后除以键的维度的平方根进行缩放。
- 应用 Softmax 函数:对注意力分数应用 Softmax 函数,得到注意力权重。
- 加权求和:将注意力权重与值向量相乘,然后求和,得到最终的输出。
多头注意力机制(Multi-Head Attention)
多头注意力机制通过将自注意力机制分成多个“头”(Head),每个头独立计算注意力,然后将结果拼接在一起,最后通过一个线性变换得到最终的输出。这样可以捕捉不同子空间的信息,提高模型的表达能力。
datasets库(Hugging Face)
datasets 是一个用于处理机器学习和深度学习任务中数据集的 Python 库。它提供了简单易用的接口来加载、处理和管理各种格式的数据集,支持本地数据集和远程数据集(如 Hugging Face 提供的公共数据集)。
pip install datasets
加载数据集load_dataset
1)加载公共数据集
from datasets import load_dataset
# 加载 IMDB 数据集
dataset = load_dataset('imdb')
print(dataset)
2)加载自定义数据集
from datasets import load_dataset
# 加载本地 CSV 文件
dataset = load_dataset('csv', data_files='path/to/your/file.csv')
print(dataset)
3)通过 map 方法对数据集中的每一行应用自定义函数
def add_length(example):
example['length'] = len(example['text'])
return example
dataset = dataset.map(add_length)
print(dataset['train'][0])
4)通过 filter 方法筛选符合条件的数据
def is_positive(example):
return example['label'] == 1
positive_dataset = dataset.filter(is_positive)
print(positive_dataset)
5)将处理后的数据集保存为本地文件
dataset.save_to_disk('path/to/save/dataset')datasets 支持与 transformers 库结合使用,方便对文本数据进行预处理(如分词、编码等)。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
def preprocess_function(examples):
return tokenizer(examples['text'], truncation=True, padding='max_length')
tokenized_datasets = dataset.map(preprocess_function, batched=True)
print(tokenized_datasets)dataset.map
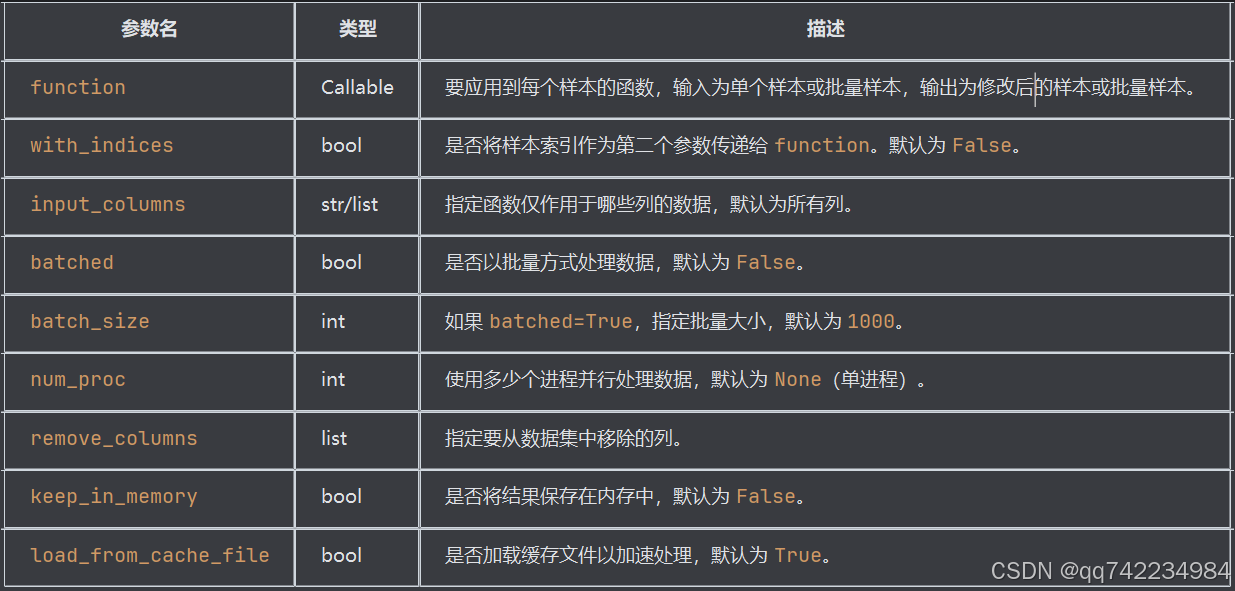
datasets.Dataset 类详解
datasets.Dataset 是 Hugging Face 的 datasets 库中的一个核心类,用于表示和操作单个数据集(如训练集或测试集)。
创建 Dataset 对象
可以通过多种方式创建 Dataset 对象,例如从字典、CSV 文件、JSON 文件等加载数据。
from datasets import Dataset
data = {
'text': ['hello', 'world'],
'label': [0, 1]
}
dataset = Dataset.from_dict(data)
print(dataset)
输出
Dataset({
features: ['text', 'label'],
num_rows: 2
})DataSet主要属性
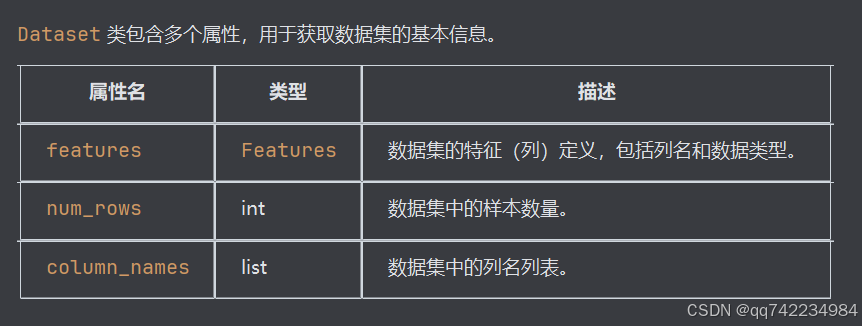
print(dataset.features)
print(dataset.num_rows)
print(dataset.column_names)
输出
{'text': Value(dtype='string'), 'label': Value(dtype='int32')}
2
['text', 'label']数据集转换

transformers库(Hugging Face)
如果想要下载大模型到本地的话,可以使用https://huggingface.co/如果在国内没有vpn是进不去的,可以使用镜像https://hf-mirror.com/或者https://opencsg.com/models。
pip install transformers主要功能
- 预训练模型:提供多种预训练模型,如BERT、RoBERTa、GPT、T5等。
- 微调模型:支持对预训练模型进行微调,以适应特定的任务和数据集。
- 多语言支持:支持多种语言的模型,适用于跨语言任务。
- 端到端管道:提供简单的API接口,用于快速构建和部署NLP应用。
模型类(库)
- 通用模型类 AutoModel 用途: 通用的预训练模型,适用于各种任务。 AutoModelForCausalLM 用途: 用于因果语言建模任务,如文本生成。 AutoModelForMaskedLM 用途: 用于掩码语言建模任务,如 BERT。 AutoModelForSeq2SeqLM 用途: 用于序列到序列任务,如翻译。
- 特定任务模型类 AutoModelForSequenceClassification 用途: 用于序列分类任务,如情感分析。 AutoModelForTokenClassification 用途: 用于标记分类任务,如命名实体识别。 AutoModelForQuestionAnswering 用途: 用于问答任务。 AutoModelForMultipleChoice 用途: 用于多项选择任务。 AutoModelForNextSentencePrediction 用途: 用于下一句预测任务。 AutoModelForTextClassification 用途: 用于文本分类任务。 AutoModelForImageClassification 用途: 用于图像分类任务。 AutoModelForSemanticSegmentation 用途: 用于语义分割任务。 AutoModelForObjectDetection 用途: 用于目标检测任务。 AutoModelForSpeechSeq2Seq 用途: 用于语音到文本任务。 AutoModelForAudioClassification 用途: 用于音频分类任务。 AutoModelForCTC 用途: 用于连接时序分类(CTC)任务。 AutoModelForSpeechClassification 用途: 用于语音分类任务。 AutoModelForTextToTextGeneration 用途: 用于文本到文本生成任务。 AutoModelForVision2Seq 用途: 用于视觉到序列生成任务。 AutoModelForTableQuestionAnswering 用途: 用于表格问答任务。 AutoModelForZeroShotClassification 用途: 用于零样本分类任务。 AutoModelForTextGeneration 用途: 用于文本生成任务。 AutoModelForSpeechToText 用途: 用于语音到文本任务。 AutoModelForTextToSpeech 用途: 用于文本到语音任务。 AutoModelForVisionTextDualEncoder 用途: 用于视觉-文本双编码任务。 AutoModelForImageToImage 用途: 用于图像到图像任务。 AutoModelForImageClassificationWithAttention 用途: 用于图像分类任务,带有注意力机制。 AutoModelForImageSegmentation 用途: 用于图像分割任务。 AutoModelForImageSuperResolution 用途: 用于图像超分辨率任务。
使用 AutoModelForSequenceClassification 进行回归任务。关键在于将 num_labels 设置为 1,并使用适当的损失函数和评估指标。
参数详解
AutoTokenizer.from_pretrained()
Hugging Face 的 transformers 库中用于加载预训练分词器的类方法。
pretrained_model_name_or_path:
- 必填参数。
- 指定预训练模型的名字(如
"bert-base-uncased")或模型文件所在的路径。 - 可以是一个 Hugging Face 提供的标准模型名称,也可以是本地存储的模型文件夹路径。
config:
- 可选参数。
- 用于指定与分词器相关的配置信息。如果未提供,方法会尝试从
pretrained_model_name_or_path中自动加载配置文件。
use_fast:
- 默认值为
True。 - 指定是否使用基于 Rust 实现的快速分词器(Fast Tokenizer)。如果设置为
False,则使用传统的 Python 分词器。
- 默认值为
cache_dir:
- 可选参数。
- 指定缓存下载模型文件的目录。如果未提供,则默认使用
~/.cache/huggingface/transformers。
force_download:
- 默认值为
False。 - 如果设置为
True,即使模型已经存在于缓存中,也会强制重新下载。
- 默认值为
local_files_only:
- 默认值为
False。 - 如果设置为
True,只允许从本地加载模型文件,不允许访问网络下载。
- 默认值为
proxies:
- 可选参数。
- 指定代理服务器的字典,例如
{'http': 'http://proxy.example.com', 'https': 'https://proxy.example.com'}。
revision:
- 默认值为
"main"。 - 指定从 Hugging Face Model Hub 加载模型时的版本分支或 commit id。
- 默认值为
subfolder:
- 可选参数。
- 如果模型存储在子文件夹中,可以指定子文件夹路径。
trust_remote_code:
- 默认值为
False。 - 如果设置为
True,允许加载远程代码中的自定义模型或分词器实现。
- 默认值为
tokenizer
Hugging Face 的 transformers 库中用于文本分词和编码的核心工具。
编码时的参数 调用 tokenizer 对文本进行编码时(如 tokenizer(text)),可以传入以下参数:
(1) 输入文本
text:
- 必填参数。
- 输入的文本字符串或列表(支持单句或多句输入)。
text_pair:
- 可选参数。
- 第二个输入文本,通常用于句子对任务(如自然语言推理)。
(2) 输出格式
return_tensors:
- 默认值为 None。
- 指定返回张量的类型:
- 'pt': 返回 PyTorch 张量。
- 'tf': 返回 TensorFlow 张量。
- 'np': 返回 NumPy 数组。
return_token_type_ids:
- 默认值为 True。
- 是否返回 token_type_ids(用于区分句子 A 和句子 B)。
return_attention_mask:
- 默认值为 True。
- 是否返回 attention_mask(用于标识有效 token 和填充部分)。
return_special_tokens_mask:
- 默认值为 False。
- 是否返回特殊标记的掩码(如 [CLS] 和 [SEP])。
(3) 截断和填充
max_length:
- 默认值为 None。
- 设置最大序列长度。超出的部分会被截断。
padding:
- 默认值为 'do_not_pad'。
- 指定是否填充序列:
- 'longest': 填充到批次中最长序列的长度。
- 'max_length': 填充到指定的 max_length。
- 'do_not_pad': 不进行填充。
truncation:
- 默认值为 False。
- 是否启用截断。如果设置为 True,超出 max_length 的部分会被截断。
stride:
- 默认值为 0。
- 在滑动窗口模式下,指定窗口之间的步幅。
(4) 其他参数
add_special_tokens:
- 默认值为 True。
- 是否添加特殊标记(如 [CLS] 和 [SEP])。
is_split_into_words:
- 默认值为 False。
- 如果输入已经是分词后的单词列表,则设置为 True。
verbose:
- 默认值为 True。
- 是否输出警告信息。
解码时的参数 调用 tokenizer.decode() 方法将 token IDs 转换回文本时,可以传入以下参数: skip_special_tokens:
- 默认值为 False。
- 是否跳过特殊标记(如 [CLS] 和 [SEP])。
clean_up_tokenization_spaces:
- 默认值为 True。
- 是否清理多余的空格。
基本使用示例
from transformers import AutoTokenizer
# 加载预训练的 BERT 分词器
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased", use_fast=True)
# 测试分词功能
text = "Hello, how are you?"
tokens = tokenizer(text)
print(tokens)
输出
{'input_ids': [101, 7592, 1010, 2023, 2003, 2860, 1012, 102], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1]}
input_ids:
表示分词后的 token IDs 列表。
每个 ID 对应词汇表中的一个 token。
示例:
101 是 [CLS] 标记(BERT 的特殊起始标记)。
102 是 [SEP] 标记(BERT 的特殊结束标记)。
其他 ID 是对应单词或子词的编码。
attention_mask:
用于标识哪些 token 是有效的输入(值为 1),哪些是填充部分(值为 0)。
在本例中,输入长度为 8,因此 attention_mask 全部为 1。如果想查看具体的 token 内容,可以使用 tokenizer.convert_ids_to_tokens 方法:
# 查看每个 token 的具体内容
tokens_decoded = tokenizer.convert_ids_to_tokens(tokens['input_ids'])
print(tokens_decoded)
输出
['[CLS]', 'hello', ',', 'how', 'are', 'you', '?', '[SEP]']
这表明输入文本被正确分词并添加了 BERT 所需的特殊标记 [CLS] 和 [SEP]。解码示例
from transformers import AutoTokenizer
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
# 编码输入文本
text = "Hello, how are you?"
tokens = tokenizer(text, return_tensors="pt", max_length=10, padding="max_length", truncation=True)
# 解码 token IDs
decoded_text = tokenizer.decode(tokens['input_ids'][0], skip_special_tokens=True)
print(decoded_text)
输出
hello, how are you?AutoModel.from_pretrained()
Hugging Face 的 transformers 库中用于加载预训练模型的核心方法。
必填参数
pretrained_model_name_or_path
- 类型: str 或 os.PathLike
- 作用: 指定预训练模型的名字或本地路径。
如果是字符串(如 "bert-base-uncased"),表示从 Hugging Face Model Hub 下载对应的模型。 如果是路径(如 ./my_model_directory),表示从本地加载模型文件。
可选参数
(1) 缓存与下载相关
cache_dir:
- 类型: str 或 os.PathLike
- 默认值: None
- 作用: 指定缓存模型文件的目录。如果未提供,默认使用 ~/.cache/huggingface/transformers。
force_download:
- 类型: bool
- 默认值: False
- 作用: 是否强制重新下载模型文件,即使它们已经存在于缓存中。
local_files_only:
- 类型: bool
- 默认值: False
- 作用: 是否只允许从本地加载模型文件,不允许访问网络下载。
proxies:
- 类型: dict
- 默认值: None
- 作用: 指定代理服务器的字典,例如 {'http': 'http://proxy.example.com', 'https': 'https://proxy.example.com'}。
revision:
- 类型: str
- 默认值: "main"
- 作用: 指定从 Hugging Face Model Hub 加载模型时的版本分支或 commit id。
subfolder:
- 类型: str
- 默认值: None
- 作用: 如果模型存储在子文件夹中,可以指定子文件夹路径。
(2) 配置相关
config:
- 类型: PretrainedConfig 或 dict
- 默认值: None
- 作用: 指定与模型相关的配置信息。如果未提供,方法会尝试从 pretrained_model_name_or_path 中自动加载配置文件。
trust_remote_code:
- 类型: bool
- 默认值: False
- 作用: 是否允许加载远程代码中的自定义模型实现。如果设置为 True,可以加载非官方支持的模型。
(3) 模型加载相关
torch_dtype:
- 类型: str, torch.dtype 或 None
- 默认值: None
- 作用: 指定模型权重的数据类型。例如:
- 'float16' 或 torch.float16: 使用半精度浮点数。
- 'bfloat16' 或 torch.bfloat16: 使用 bfloat16 数据类型。
- 'float32' 或 torch.float32: 使用单精度浮点数(默认)。
low_cpu_mem_usage:
- 类型: bool
- 默认值: False
- 作用: 是否启用低 CPU 内存占用模式。适用于加载大模型时减少内存消耗。
device_map:
- 类型: str 或 Dict[str, Union[int, str]]
- 默认值: None
- 作用: 指定模型在多设备(如 GPU)上的分布策略。例如:
- 'auto': 自动分配模型到可用设备。
- 'balanced': 平衡地分配模型到多个 GPU。
- {layer_name: device_id}: 手动指定每一层的设备。
offload_folder:
- 类型: str 或 os.PathLike
- 默认值: None
- 作用: 指定将部分模型权重卸载到磁盘的文件夹路径。适用于内存有限的环境。
offload_state_dict:
- 类型: bool
- 默认值: False
- 作用: 是否在加载过程中将状态字典卸载到磁盘。
use_auth_token:
- 类型: str 或 bool
- 默认值: None
- 作用: 如果需要访问私有模型,可以提供 Hugging Face 的访问令牌。
model
常用属性

from transformers import AutoModel
model = AutoModel.from_pretrained("bert-base-uncased")
print(model.config)
输出
BertConfig {
"architectures": [
"BertModel"
],
"attention_probs_dropout_prob": 0.1,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"transformers_version": "4.25.1",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 30522
}常用方法
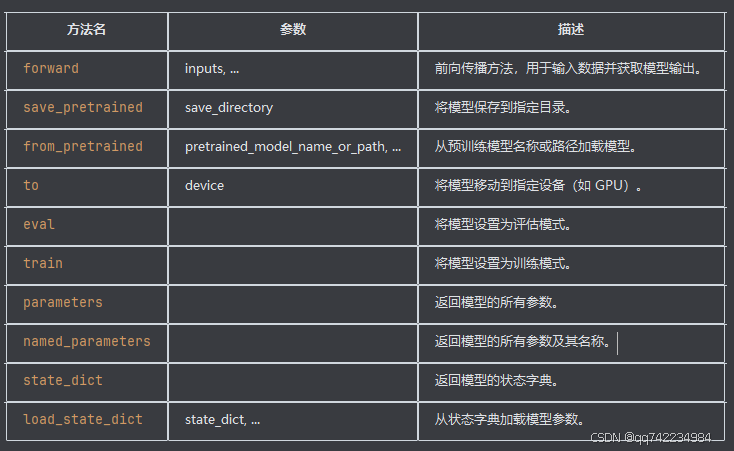 forward 方法是模型的前向传播方法,用于输入数据并获取模型输出。常见的输入参数包括:
forward 方法是模型的前向传播方法,用于输入数据并获取模型输出。常见的输入参数包括:
- input_ids: 输入的 token ID 序列。
- attention_mask: 可选,用于指定哪些 token 需要关注。
- token_type_ids: 可选,用于区分不同类型的 token(如句子 A 和句子 B)。
- position_ids: 可选,用于指定 token 的位置。
- head_mask: 可选,用于指定哪些注意力头需要使用。
- inputs_embeds: 可选,用于直接输入嵌入向量。
- output_attentions: 可选,是否返回注意力权重。
- output_hidden_states: 可选,是否返回所有隐藏状态。
- return_dict: 可选,是否返回 ModelOutput 对象。
import torch
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModel.from_pretrained("bert-base-uncased")
# 编码输入文本
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
# 前向传播
with torch.no_grad():
outputs = model(**inputs)
# 获取最后一层的隐藏状态
last_hidden_states = outputs.last_hidden_state
print(last_hidden_states.shape) # 输出: torch.Size([1, 10, 768])
# 获取所有隐藏状态
all_hidden_states = outputs.hidden_states
print(len(all_hidden_states)) # 输出: 13 (12 层隐藏状态 + 1 层嵌入)
# 获取注意力权重
attention_weights = outputs.attentions
print(len(attention_weights)) # 输出: 12 (12 层注意力权重)model.generate 方法详解
model.generate 是 Hugging Face 的 transformers 库中用于生成文本的主要方法。它广泛应用于各种生成任务,如文本生成、对话系统、摘要生成等。 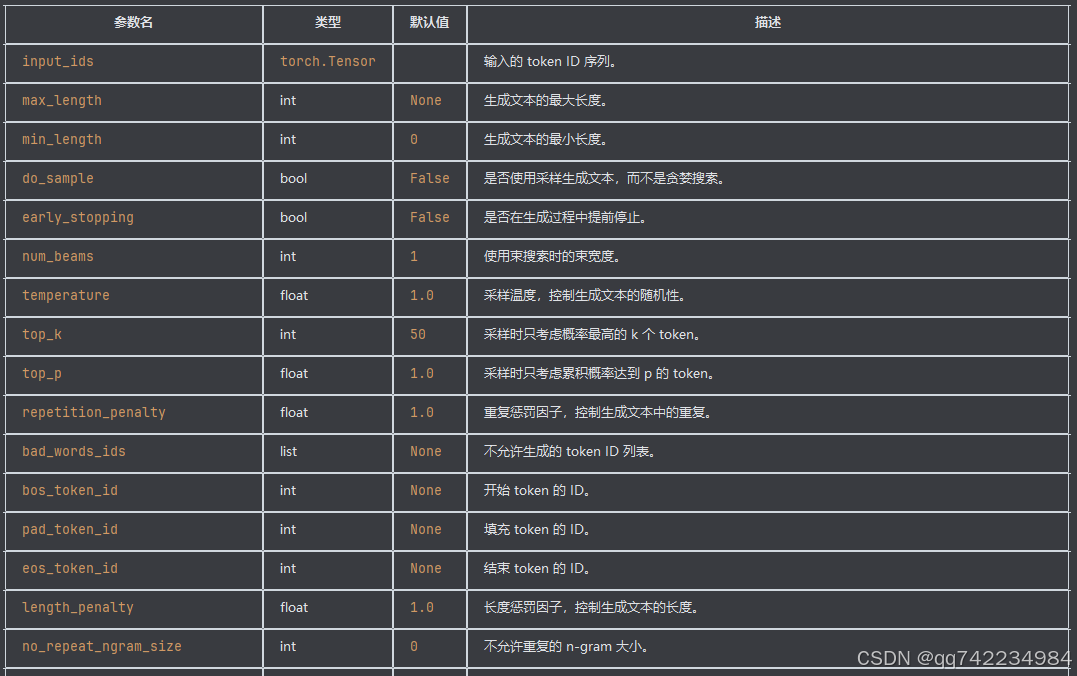
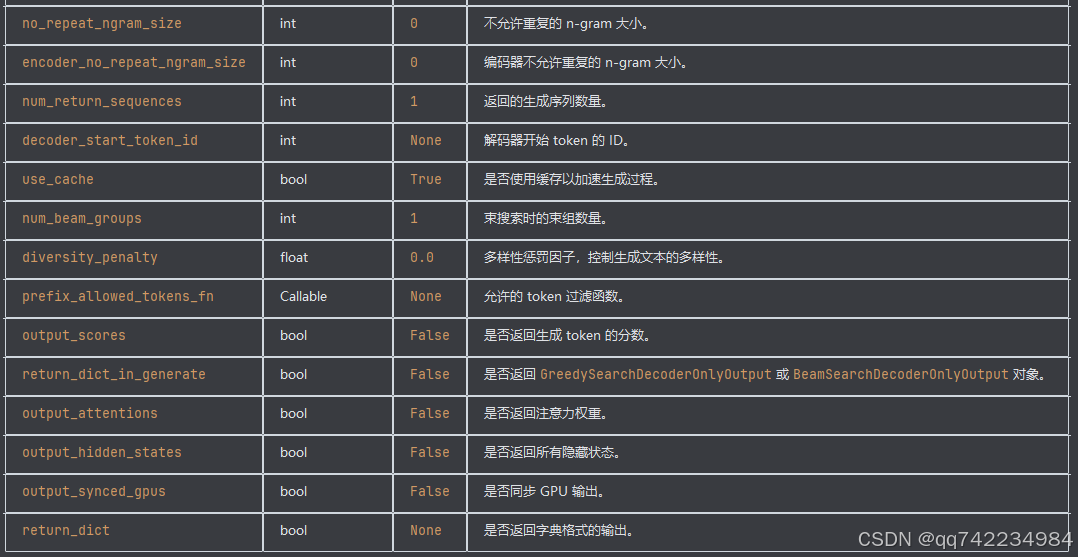
AutoConfig.from_pretrained()
AutoConfig.from_pretrained() 是 Hugging Face Transformers 库中用于加载预训练模型配置的核心方法。
pretrained_model_name_or_path
- 类型:str 或 os.PathLike
- 描述:指定预训练模型的名称或路径。可以是模型的标识符(如 'bert-base-uncased')或本地路径,指向包含配置文件(通常是 config.json)的目录。
cache_dir
- 类型:str 或 os.PathLike,可选
- 描述:指定缓存目录,用于存储从远程下载的配置文件。默认使用库的默认缓存目录。
force_download
- 类型:bool,可选
- 描述:是否强制重新下载配置文件,即使它已经存在于缓存中。默认值为 False。
resume_download
- 类型:bool,可选
- 描述:如果下载中断,是否从中断处继续下载。默认值为 False。
proxies
- 类型:dict,可选
- 描述:指定代理服务器,用于通过代理下载配置文件。
use_auth_token
- 类型:str 或 bool,可选
- 描述:用于访问私有模型的认证令牌。如果为 True,会尝试从环境变量 HF_AUTH_TOKEN 中读取令牌;如果是字符串,则直接作为认证令牌。
revision
- 类型:str,可选
- 描述:指定模型的版本或分支(如 "main" 或 Git 提交哈希)。默认值为 "main"。
local_files_only
- 类型:bool,可选
- 描述:是否仅使用本地文件,而不尝试从远程下载。默认值为 False。
config
在使用 AutoConfig.from_pretrained() 加载配置对象后,config 对象包含了与预训练模型相关的各种配置参数。
model_type
- 类型:str
- 描述:模型的类型,例如 'bert'、'gpt2'、'roberta' 等。
vocab_size
- 类型:int
- 描述:词汇表的大小。
hidden_size
- 类型:int
- 描述:隐藏层的大小。
num_hidden_layers
- 类型:int
- 描述:隐藏层的数量。
num_attention_heads
- 类型:int
- 描述:注意力头的数量。
intermediate_size
- 类型:int
- 描述:中间层的大小。
hidden_act
- 类型:str
- 描述:隐藏层激活函数的类型,例如 'gelu'、'relu' 等。
hidden_dropout_prob
- 类型:float
- 描述:隐藏层的 dropout 概率。
attention_probs_dropout_prob
- 类型:float
- 描述:注意力概率的 dropout 概率。
max_position_embeddings
- 类型:int
- 描述:最大位置嵌入的数量。
type_vocab_size
- 类型:int
- 描述:类型词汇表的大小(主要用于 BERT 等模型)。
initializer_range
- 类型:float
- 描述:初始化权重的范围。
layer_norm_eps
- 类型:float
- 描述:层归一化的 epsilon 值。
num_labels
- 类型:int
- 描述:分类任务的标签数量。
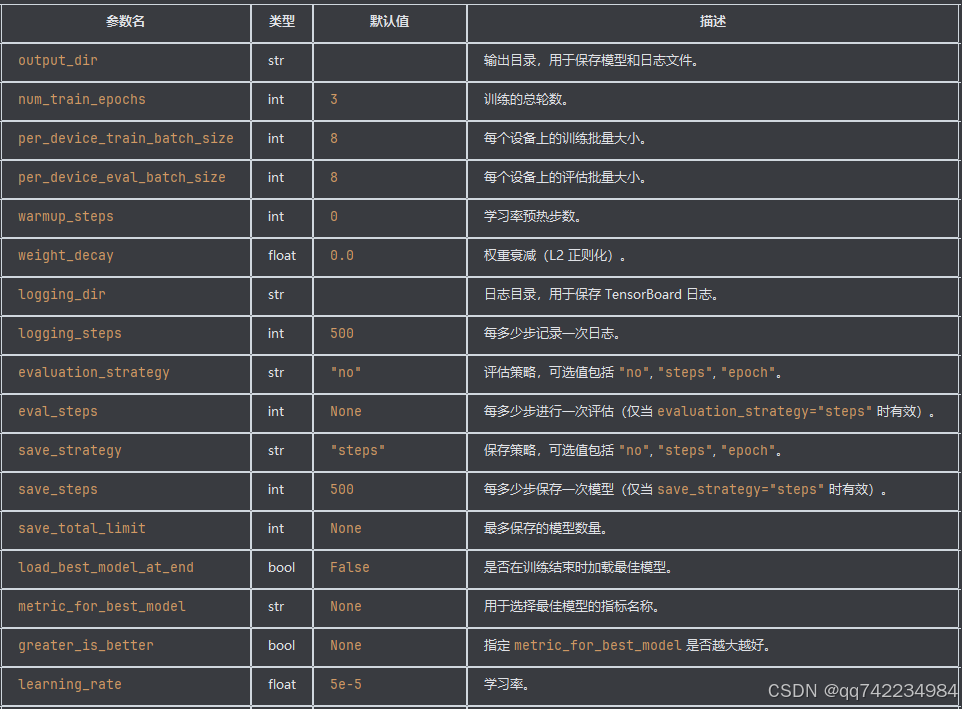
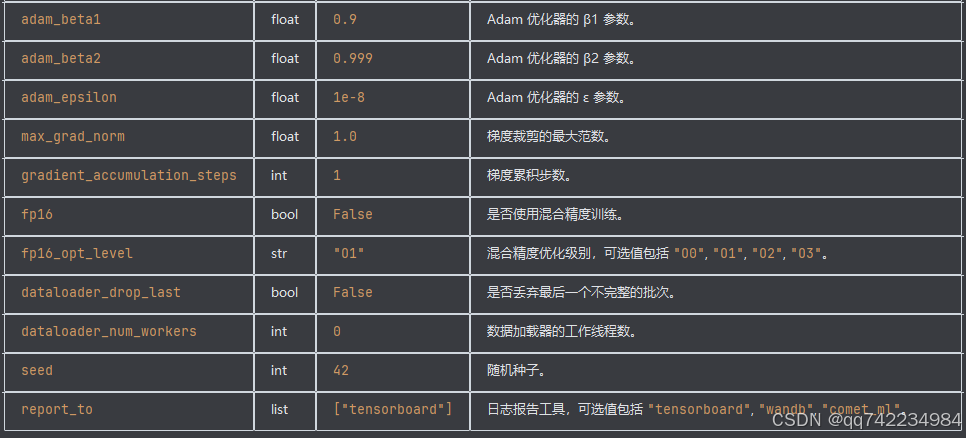
TrainingArguments
Hugging Face 的 transformers 库中的一个类,用于配置训练过程中的各种参数。通过 TrainingArguments,你可以轻松地控制训练的各个方面,包括训练步数、学习率、批量大小、评估策略等。
常用参数
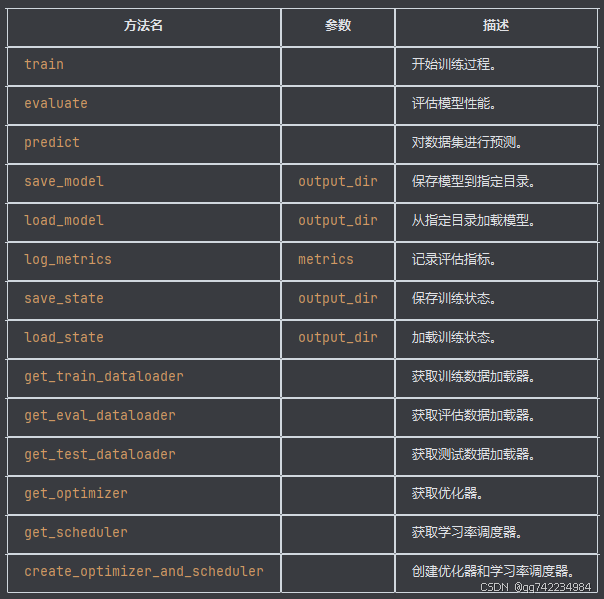
Trainer
Hugging Face 的 transformers 库中的一个核心类,用于简化模型的训练、评估和预测过程。
常用参数
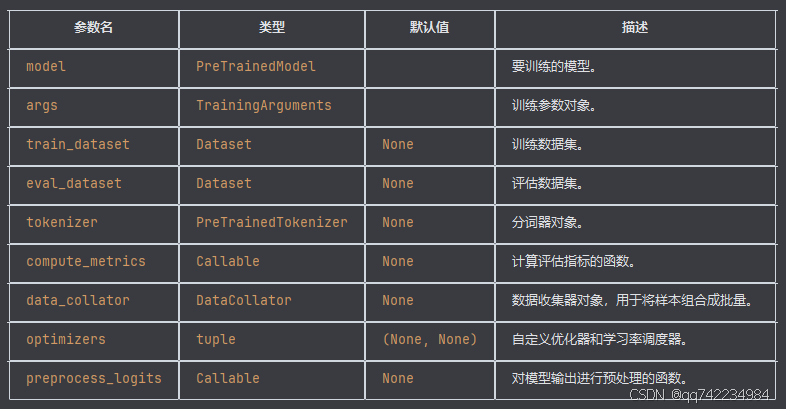
1)compute_metrics 指定计算评估指标的函数。
import numpy as np
from datasets import load_metric
metric = load_metric("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
2)optimizers 指定自定义优化器和学习率调度器。
from transformers import AdamW, get_scheduler
optimizer = AdamW(model.parameters(), lr=2e-5)
lr_scheduler = get_scheduler(
name="linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=trainer.get_train_dataloader().num_batches * training_args.num_train_epochs,
)
optimizers = (optimizer, lr_scheduler)常用方法
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset, load_metric
from transformers import DataCollatorWithPadding
# 加载数据集
dataset = load_dataset("glue", "mrpc")
# 加载预训练的 BERT 模型和分词器
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2)
# 编码数据集
def tokenize_function(examples):
return tokenizer(examples['sentence1'], examples['sentence2'], truncation=True, padding='max_length')
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# 创建数据收集器
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
# 创建评估指标函数
metric = load_metric("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
# 创建训练参数
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
warmup_steps=500,
weight_decay=0.01,
logging_dir="./logs",
logging_steps=100,
evaluation_strategy="steps",
eval_steps=500,
save_strategy="steps",
save_steps=500,
save_total_limit=3,
load_best_model_at_end=True,
metric_for_best_model="eval_loss",
greater_is_better=False,
learning_rate=2e-5,
adam_beta1=0.9,
adam_beta2=0.999,
adam_epsilon=1e-8,
max_grad_norm=1.0,
gradient_accumulation_steps=2,
fp16=True,
fp16_opt_level="O1",
dataloader_drop_last=True,
dataloader_num_workers=4,
seed=42,
report_to=["tensorboard", "wandb"],
)
# 创建 Trainer 对象
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets['train'],
eval_dataset=tokenized_datasets['validation'],
tokenizer=tokenizer,
compute_metrics=compute_metrics,
data_collator=data_collator,
)
# 开始训练
trainer.train()
# 评估模型
eval_results = trainer.evaluate()
print(eval_results)
# 预测
predictions = trainer.predict(tokenized_datasets['validation'])
print(predictions)LogitsProcess 和 LogitsProcessList 详解
LogitsProcess 是一个接口或基类,通常用于定义对 logits(模型输出的未归一化的预测值)进行处理的逻辑。它的主要作用是对模型生成的 logits 进行特定的后处理操作,例如温度调整、去重复、长度惩罚等。
LogitsProcess常见功能
- 温度采样 (Temperature Sampling):通过调整温度参数来控制生成文本的多样性。
- Top-K 采样:仅保留概率最高的 K 个词,并从这些词中随机选择下一个词。
- Top-P (Nucleus) 采样:保留累积概率达到阈值 P 的最小词集合,并从中随机选择。
- 重复惩罚 (Repetition Penalty):降低已经生成过的词的概率,避免重复生成。
- 长度惩罚 (Length Penalty):根据生成序列的长度调整概率分布。
LogitsProcessList 是一个容器类,用于存储多个 LogitsProcessor 对象。它允许将多个不同的 logits 处理逻辑组合在一起,在生成过程中依次应用这些处理逻辑。
LogitsProcessList工作原理
- 在每次生成步骤中,LogitsProcessList 会遍历其内部的所有 LogitsProcessor,并对 logits 应用每个处理器的逻辑。
- 最终返回经过所有处理器处理后的 logits。
Modelscope
ModelScope 是阿里云开源的模型即服务(MaaS)平台,提供丰富的预训练模型。
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-30B-A3B"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Switch between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)示例
使用Transformers库加载本地qwen2.5b模型进行回归预测
步骤1:准备环境
import torch
from torch.utils.data import Dataset, DataLoader
from transformers import AutoModel, AutoConfig, AutoTokenizer
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
# 检查设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")步骤2:数据处理
class SolarDataset(Dataset):
def __init__(self, features, targets):
self.features = features
self.targets = targets
def __len__(self):
return len(self.features)
def __getitem__(self, idx):
return {
'input_features': torch.tensor(self.features[idx], dtype=torch.float32),
'labels': torch.tensor(self.targets[idx], dtype=torch.float32)
}
# 假设df是你的DataFrame
features = df[['辐照度', '温度', '湿度', '压强']].values
target = df['实发功率'].values
# 数据标准化
scaler = StandardScaler()
scaled_features = scaler.fit_transform(features)
# 划分数据集
X_train, X_val, y_train, y_val = train_test_split(
scaled_features, target, test_size=0.2, random_state=42
)
train_dataset = SolarDataset(X_train, y_train)
val_dataset = SolarDataset(X_val, y_val)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32)步骤3:修改模型结构
class QwenRegression(torch.nn.Module):
def __init__(self, model_path):
super().__init__()
config = AutoConfig.from_pretrained(model_path)
# 加载本地模型
self.base_model = AutoModel.from_pretrained(
model_path,
config=config
)
# 添加适配层(将4个特征映射到模型维度)
self.feature_adapter = torch.nn.Linear(4, config.hidden_size)
# 回归头
self.regressor = torch.nn.Linear(config.hidden_size, 1)
# 冻结基础模型参数(可选)
for param in self.base_model.parameters():
param.requires_grad = False
def forward(self, input_features):
# 特征适配
adapted = self.feature_adapter(input_features)
# 添加虚拟token维度 (batch_size, seq_len=1, hidden_size)
adapted = adapted.unsqueeze(1)
# 通过基础模型
outputs = self.base_model(inputs_embeds=adapted)
# 取最后一个隐藏状态
last_hidden = outputs.last_hidden_state[:, 0, :]
# 回归预测
return self.regressor(last_hidden).squeeze(-1)步骤4:训练配置
# 初始化模型
model_path = "path/to/your/local/qwen2.5b"
model = QwenRegression(model_path).to(device)
# 训练参数
criterion = torch.nn.MSELoss()
optimizer = torch.optim.AdamW([
{'params': model.feature_adapter.parameters()},
{'params': model.regressor.parameters()}
], lr=1e-4)
# 评估函数
def evaluate(model, dataloader):
model.eval()
total_loss = 0
with torch.no_grad():
for batch in dataloader:
inputs = batch['input_features'].to(device)
labels = batch['labels'].to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
total_loss += loss.item()
return total_loss / len(dataloader)步骤5:训练循环
num_epochs = 20
best_val_loss = float('inf')
for epoch in range(num_epochs):
model.train()
train_loss = 0
for batch in train_loader:
optimizer.zero_grad()
inputs = batch['input_features'].to(device)
labels = batch['labels'].to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
val_loss = evaluate(model, val_loader)
print(f"Epoch {epoch+1}/{num_epochs}")
print(f"Train Loss: {train_loss/len(train_loader):.4f}")
print(f"Val Loss: {val_loss:.4f}\n")
# 保存最佳模型
if val_loss < best_val_loss:
best_val_loss = val_loss
torch.save(model.state_dict(), "best_model.pth")- 可尝试尝试解冻部分基础模型层(如最后3层)
使用AutoModelForSequenceClassification,并指定num_labels=1进行回归预测
参考
1.基于本地Qwen2-7b-Instruct模型做回归预测 2.https://github.com/datawhalechina/unlock-hf 3.https://modelscope.cn/docs/intro/quickstart 4.https://qwenlm.github.io/blog/qwen3/