@[TOC](Windows Docker部署PaddleOCR-VL:基于Blackwell架构GPU与vLLM的高性能VLM配置指南) 
一、概述
PaddleOCR-VL 是基于 PaddlePaddle 的视觉语言模型(VLM),支持图像中的文字检测、识别与结构化理解。本指南旨在帮助用户在 Windows Docker 环境中,利用 NVIDIA Blackwell 架构 GPU 及 vLLM 推理加速框架,完成 PaddleOCR-VL 的高性能部署与调优。
二、PaddleOCR-VL 简介
见官网说明:使用教程 - PaddleOCR 文档
三、vLLM 详解
vLLM(Very Large Language Model Serving)是一个专为大规模语言模型推理设计的高性能服务框架,由加州大学伯克利分校的研究团队开发。其核心创新在于 PagedAttention 算法,通过优化的内存管理机制显著提高了 GPU 显存利用率和推理吞吐量。
3.1 核心架构与设计理念
3.1.1 主要特点
- 高性能推理:相比传统服务框架(如 Hugging Face Transformers),vLLM 在相同硬件上可实现 最高 24 倍 的吞吐量提升
- 高效内存管理:采用 PagedAttention 技术,减少内存碎片,提高显存利用率
- 连续批处理:支持动态批处理,自动合并来自不同请求的 token
- 兼容性强:提供与 OpenAI API 兼容的接口,易于集成到现有系统
3.1.2 核心组件
vLLM 架构:
┌─────────────────────────────────────────┐
│ 客户端请求 │
└─────────────────┬───────────────────────┘
│
┌─────────────────▼───────────────────────┐
│ vLLM 服务层 │
│ ┌─────────────┐ ┌─────────────────┐ │
│ │ 调度器 │ │ 批处理引擎 │ │
│ │ (Scheduler) │ │ (Batching) │ │
│ └─────────────┘ └─────────────────┘ │
│ │ │
│ ┌───────▼───────┐ │
│ │ PagedAttention │ │
│ │ 内存管理 │ │
│ └───────┬───────┘ │
└──────────────────┼──────────────────────┘
│
┌────────▼────────┐
│ GPU 显存池 │
│ (Memory Pool) │
└─────────────────┘3.2 关键技术:PagedAttention
3.2.1 传统注意力机制的内存问题
传统 Transformer 模型在推理时,KV(Key-Value)缓存通常需要连续的内存空间:
- 内存碎片严重:不同序列长度导致显存利用不充分
- OOM 风险高:长序列容易导致显存溢出
- 资源浪费:短序列无法充分利用已分配内存
3.2.2 PagedAttention 解决方案
PagedAttention 借鉴操作系统虚拟内存的分页机制:
- 分块存储:将 KV 缓存分割成固定大小的"块"(如 16 个 token/块)
- 动态分配:按需分配块,避免预先分配大块连续内存
- 内存共享:相同提示词的多个请求可共享 KV 缓存块
传统方式:
┌─────────────────────────────────────────┐
│ Sequence 1: 1024 tokens │
│ (连续内存分配) │
└─────────────────────────────────────────┘
PagedAttention:
┌───┬───┬───┬───┬───┬───┐
│块1│块2│块3│块4│块5│...│
└───┴───┴───┴───┴───┴───┘
↑ ↑ ↑ ↑
序列A 序列B 序列A 序列C3.2.3 性能优势
- 显存利用率提升:最高可达 99%(传统方法通常为 60-70%)
- 吞吐量增加:支持更大批量处理,提高 GPU 利用率
- 延迟降低:减少内存分配和碎片整理开销
四、环境准备:Windows Docker 与 NVIDIA GPU 支持
在 Windows 上使用 Docker 进行 GPU 加速部署,核心是配置好 NVIDIA Container Toolkit(原 nvidia-docker)。这是让 Docker 容器访问宿主机 GPU 驱动的基础。
4.1 系统与驱动要求
- Windows 版本:确保系统支持 WSL 2(Windows Subsystem for Linux 2),这是当前在 Windows 上运行 Docker 并启用 GPU 加速的推荐方式
- NVIDIA 驱动:确认驱动支持 CUDA 12.9 或以上版本(可通过 NVIDIA app或官网更新驱动)
- GPU 支持列表(NVIDIA Blackwell 架构):
- RTX 5090、RTX 5080、RTX 5070、RTX 5070 Ti、RTX 5060、RTX 5060 Ti、RTX 5050
Blackwell 架构优势
Blackwell 架构相比上一代 Hopper 架构在以下方面有明显提升:
- 显存带宽更高:支持更快的模型加载与推理
- 能效比优化:相同任务功耗更低
- 第二代 Transformer 引擎:针对 LLM 推理进一步优化
4.2 环境检查步骤
打开 PowerShell(管理员身份),运行:
powershellwsl --version确保 WSL 版本为 2 或更高。
运行:
powershellnvidia-smi查看驱动版本与 CUDA 支持情况。
五、Docker 部署 PaddleOCR-VL 核心服务
PaddleOCR-VL 的完整部署包含两部分:版面检测模型和 VLM 推理服务。
5.1 使用官方集成镜像(推荐)
PaddleOCR 提供了 Docker 镜像,用于快速启动 vLLM 推理服务。可使用以下命令启动服务(要求 Docker 版本 ≥ 19.03):
docker run -it --rm --gpus all --network host ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddleocr-genai-vllm-server:latest-gpu-sm120 paddleocr genai_server --model_name PaddleOCR-VL-0.9B --host 0.0.0.0 --port 8118 --backend vllm离线环境部署
若无法连接互联网,可使用离线版本镜像(约 14 GB):
docker run -it --rm --gpus all --network host ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddleocr-genai-vllm-server:latest-gpu-sm120-offline paddleocr genai_server --model_name PaddleOCR-VL-0.9B --host 0.0.0.0 --port 8118 --backend vllm端口映射(可选)
如需将容器端口映射到宿主机:
docker run -it --rm --gpus all -p 8118:8118 -p 8080:8080 <image_id>六、性能优化与推理加速
6.1 vLLM 关键参数调优
以下参数可用于提升推理性能与资源利用率:
| 参数 | 说明 | 建议值 |
|---|---|---|
--gpu-memory-utilization | GPU 显存使用比例(0~1) | 0.8 |
--max-num-batched-tokens | 批处理最大 token 数 | 16384(OCR任务建议) |
--max-model-len | 模型最大上下文长度 | 7520 |
示例启动命令(含性能调优):
paddleocr genai_server --model_name PaddleOCR-VL-0.9B --host 0.0.0.0 --port 8118 --backend vllm --backend_config <(echo -e 'gpu-memory-utilization: 0.8\nmax-model-len: 7520\nmax-num-batched-tokens: 32768')6.2 服务监控与健康检查
部署后,可使用以下命令检查服务状态:
curl http://localhost:8118/health若返回 StatusCode : 200 StatusDescription : OK Content : {} RawContent : HTTP/1.1 200 OK Content-Length: 0,说明服务运行正常。
补充监控建议:
- 使用
nvidia-smi监控 GPU 利用率 - 使用
docker stats查看容器资源使用情况 - 通过日志查看推理耗时与吞吐量
七、客户端调用示例
7.1 Python API 调用
安装 PaddleOCR 客户端库后,可通过以下代码调用服务:
from paddleocr import PaddleOCRVL
pipeline = PaddleOCRVL(
vl_rec_backend="vllm-server",
vl_rec_server_url="http://127.0.0.1:8118/v1"
)
# 处理图片
result = pipeline.ocr("path/to/image.jpg", cls=True)
print(result)7.2 CLI 命令行调用
paddleocr doc_parser --input paddleocr_vl_demo.png --vl_rec_backend vllm-server --vl_rec_server_url http://127.0.0.1:8118/v1八、vLLM 参数分类说明
8.1 模型加载与基本配置
| 参数 | 说明 |
|---|---|
--model_name | 模型名称,如 PaddleOCR-VL-0.9B |
--backend | 推理后端,应设置为 vllm |
8.2 推理性能与资源管理
| 参数 | 说明 |
|---|---|
--gpu-memory-utilization | GPU 显存使用比例 |
--max-num-batched-tokens | 批处理 token 上限 |
--max-model-len | 模型上下文最大长度 |
8.3 服务部署与网络配置
| 参数 | 说明 |
|---|---|
--host | 服务绑定地址,如 0.0.0.0 |
--port | 服务端口,如 8118 |
--backend_config | 可选,用于传递 YAML 格式的 vLLM 配置 |
九、 服务化部署
9.1 整体架构
PaddleOCR‑VL 服务化部署采用前后端分离架构,通过 Docker Compose 编排以下两个容器服务:
- paddleocr‑vl‑api – 对外提供 OCR 和视觉语言模型 API 接口(前端服务)
- paddleocr‑vlm‑server – 视觉语言模型推理服务后端(后端服务)
两个服务均支持 GPU 加速,适用于生产环境部署。
9.2 使用 Docker Compose 部署(推荐)
步骤一:准备配置文件
1. 创建 compose.yaml
services:
paddleocr-vl-api:
image: ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddleocr-vl:${API_IMAGE_TAG_SUFFIX}
container_name: paddleocr-vl-api
ports:
- 8080:8080
depends_on:
paddleocr-vlm-server:
condition: service_healthy
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ["0"]
capabilities: [gpu]
user: root
restart: unless-stopped
environment:
- VLM_BACKEND=${VLM_BACKEND:-vllm}
command: /bin/bash -c "paddlex --serve --pipeline /home/paddleocr/pipeline_config_${VLM_BACKEND}.yaml"
healthcheck:
test: ["CMD-SHELL", "curl -f http://localhost:8080/health || exit 1"]
paddleocr-vlm-server:
image: ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddleocr-genai-${VLM_BACKEND}-server:${VLM_IMAGE_TAG_SUFFIX}
container_name: paddleocr-vlm-server
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ["0"]
capabilities: [gpu]
user: root
restart: unless-stopped
healthcheck:
test: ["CMD-SHELL", "curl -f http://localhost:8080/health || exit 1"]
start_period: 300s2. 创建 .env 环境变量文件
API_IMAGE_TAG_SUFFIX=latest-gpu-sm120-offline
VLM_BACKEND=vllm
VLM_IMAGE_TAG_SUFFIX=latest-gpu-sm120-offline步骤二:启动服务
在 compose.yaml 和 .env 所在目录执行:
docker compose up启动成功后,日志将显示:
paddleocr-vl-api | INFO: Started server process [1]
paddleocr-vl-api | INFO: Waiting for application startup.
paddleocr-vl-api | INFO: Application startup complete.
paddleocr-vl-api | INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)服务默认监听 8080 端口。
步骤三:验证服务
访问健康检查接口:
curl http://localhost:8080/health或使用客户端调用示例进行功能验证。
9.3 服务详解
9.3.1 paddleocr‑vl‑api(前端服务)
| 配置项 | 说明 |
|---|---|
image | PaddleOCR‑VL 服务镜像,标签通过 API_IMAGE_TAG_SUFFIX 环境变量指定 |
ports | 端口映射,格式为 宿主机端口:容器端口 |
depends_on | 依赖后端服务,并设置健康检查条件 |
deploy.resources | GPU 资源配置,支持指定 GPU 设备 ID |
user | 容器运行用户(目前为 root,后续计划改为普通用户) |
environment | 环境变量,VLM_BACKEND 指定推理后端(默认为 vllm) |
command | 启动命令,动态加载对应后端的 pipeline 配置文件 |
healthcheck | 健康检查机制,通过调用 /health 接口判断服务状态 |
9.3.2 paddleocr‑vlm‑server(后端服务)
| 配置项 | 说明 |
|---|---|
image | VLM 推理服务镜像,镜像标签由 VLM_BACKEND 和 VLM_IMAGE_TAG_SUFFIX 决定 |
deploy.resources | GPU 资源配置,与前端服务保持一致 |
healthcheck | 健康检查,设置 start_period 以避免启动初期误判 |
9.4 自定义配置
9.4.1 修改服务端口
如需将服务端口改为 8111,编辑 compose.yaml 中 paddleocr-vl-api.ports:
ports:
- - 8080:8080
+ - 8111:80809.4.2 指定使用的 GPU
如需使用 GPU 卡 1,修改 compose.yaml 中两个服务的 device_ids:
devices:
- driver: nvidia
- device_ids: ["0"]
+ device_ids: ["1"]
capabilities: [gpu]9.4.3 调整 VLM 服务端配置
若需自定义 VLM 服务端参数,可生成配置文件并挂载至容器。
- 生成配置文件(例如
vlm_server_config.yaml)
gpu-memory-utilization: 0.8
max-model-len: 7520
max-num-batched-tokens: 32768- 在
compose.yaml的paddleocr-vlm-server服务中添加以下配置:
volumes:
- /path/to/your_config.yaml:/home/paddleocr/vlm_server_config.yaml
command: paddleocr genai_server --model_name PaddleOCR-VL-0.9B --host 0.0.0.0 --port 8080 --backend vllm --backend_config /home/paddleocr/vlm_server_config.yaml9.5 vLLM后端对应的产线配置文件:pipeline_config_vllm.yaml
pipeline_name: PaddleOCR-VL
batch_size: 64
use_queues: True
use_doc_preprocessor: False
use_layout_detection: True
use_chart_recognition: False
format_block_content: False
SubModules:
LayoutDetection:
module_name: layout_detection
model_name: PP-DocLayoutV2
model_dir: null
batch_size: 8
threshold:
0: 0.5 # abstract
1: 0.5 # algorithm
2: 0.5 # aside_text
3: 0.5 # chart
4: 0.5 # content
5: 0.4 # formula
6: 0.4 # doc_title
7: 0.5 # figure_title
8: 0.5 # footer
9: 0.5 # footer
10: 0.5 # footnote
11: 0.5 # formula_number
12: 0.5 # header
13: 0.5 # header
14: 0.5 # image
15: 0.4 # formula
16: 0.5 # number
17: 0.4 # paragraph_title
18: 0.5 # reference
19: 0.5 # reference_content
20: 0.45 # seal
21: 0.5 # table
22: 0.4 # text
23: 0.4 # text
24: 0.5 # vision_footnote
layout_nms: True
layout_unclip_ratio: [1.0, 1.0]
layout_merge_bboxes_mode:
0: "union" # abstract
1: "union" # algorithm
2: "union" # aside_text
3: "large" # chart
4: "union" # content
5: "large" # display_formula
6: "large" # doc_title
7: "union" # figure_title
8: "union" # footer
9: "union" # footer
10: "union" # footnote
11: "union" # formula_number
12: "union" # header
13: "union" # header
14: "union" # image
15: "large" # inline_formula
16: "union" # number
17: "large" # paragraph_title
18: "union" # reference
19: "union" # reference_content
20: "union" # seal
21: "union" # table
22: "union" # text
23: "union" # text
24: "union" # vision_footnote
VLRecognition:
module_name: vl_recognition
model_name: PaddleOCR-VL-0.9B
model_dir: null
batch_size: 4096
genai_config:
backend: vllm-server
server_url: http://paddleocr-vlm-server:8080/v1
SubPipelines:
DocPreprocessor:
pipeline_name: doc_preprocessor
batch_size: 8
use_doc_orientation_classify: True
use_doc_unwarping: True
SubModules:
DocOrientationClassify:
module_name: doc_text_orientation
model_name: PP-LCNet_x1_0_doc_ori
model_dir: null
batch_size: 8
DocUnwarping:
module_name: image_unwarping
model_name: UVDoc
model_dir: null9.5.1 配置说明补充
batch_size: 64:全局批处理大小,建议根据 GPU 显存调整use_queues: True:启用异步队列,适合高并发场景use_doc_preprocessor: False:如文档已预处理,可关闭以提升速度batch_size: 4096(VLRecognition):针对 vLLM 的 token 批处理大小,影响吞吐量
9.5.2 版面检测模块(LayoutDetection)
9.5.2.1 基本配置
module_name: layout_detection # 模块类型
model_name: PP-DocLayoutV2 # 使用最新版布局检测模型
model_dir: null # 使用默认模型路径
batch_size: 8 # 布局检测批处理大小模型特性:
- PP-DocLayoutV2:支持 25 种版面元素检测
- 相比 V1 版本,精度提升 15%,速度提升 30%
9.5.2.2 类别阈值配置(0-24类)
配置文件中详细定义了 25 类版面元素的置信度阈值:
| 类别ID | 类别名称 | 阈值 | 说明 |
|---|---|---|---|
| 0 | abstract | 0.5 | 摘要 |
| 1 | algorithm | 0.5 | 算法 |
| 2 | aside_text | 0.5 | 旁注文本 |
| 3 | chart | 0.5 | 图表 |
| 4 | content | 0.5 | 内容区域 |
| 5 | formula | 0.4 | 公式 |
| 6 | doc_title | 0.4 | 文档标题 |
| 7 | figure_title | 0.5 | 图标题 |
| 8 | footer | 0.5 | 页脚 |
| 9 | footer | 0.5 | 页脚(重复) |
| 10 | footnote | 0.5 | 脚注 |
| 11 | formula_number | 0.5 | 公式编号 |
| 12 | header | 0.5 | 页眉 |
| 13 | header | 0.5 | 页眉(重复) |
| 14 | image | 0.5 | 图像 |
| 15 | formula | 0.4 | 行内公式 |
| 16 | number | 0.5 | 编号 |
| 17 | paragraph_title | 0.4 | 段落标题 |
| 18 | reference | 0.5 | 参考文献 |
| 19 | reference_content | 0.5 | 参考文献内容 |
| 20 | seal | 0.45 | 印章 |
| 21 | table | 0.5 | 表格 |
| 22 | text | 0.4 | 文本 |
| 23 | text | 0.4 | 文本(重复) |
| 24 | vision_footnote | 0.5 | 视觉脚注 |
阈值设计原则:
- 高阈值(0.5):用于结构化元素(表格、图表、标题),确保高精度
- 中等阈值(0.4-0.45):用于文本和公式,平衡召回率和准确率
- 低阈值(0.4):用于段落文本,提高召回率
9.5.2.3 后处理参数
layout_nms: True # 启用非极大值抑制,消除重叠框
layout_unclip_ratio: [1.0, 1.0] # 边界框扩展比例(宽度,高度)9.5.2.4 边界框合并策略
layout_merge_bboxes_mode:
0: "union" # abstract - 并集合并
1: "union" # algorithm - 并集合并
2: "union" # aside_text - 并集合并
3: "large" # chart - 保留大面积框
4: "union" # content - 并集合并
5: "large" # display_formula - 保留大面积框
# ... 其他类别合并策略说明:
"union":合并重叠框为并集(适合文本区域)"large":保留面积最大的框(适合图表、公式等独立元素)"none":不合并(保留所有检测框)
9.5.3 应用配置文件
若您使用 Docker Compose 部署:
设置 Compose 文件中的 services.paddleocr-vl-api.volumes 字段,将产线配置文件挂载到 /home/paddleocr 目录。例如:
services:
paddleocr-vl-api:
...
volumes:
- pipeline_config_vllm.yaml:/home/paddleocr/pipeline_config.yaml
...在生产环境中,您也可以自行构建镜像,将配置文件打包到镜像中。
若您是手动部署:
在启动服务时,将 --pipeline 参数指定为自定义配置文件路径。
9.6 客户端调用
9.6.1 API 参考
接口说明
- 端点:
POST /layout-parsing - 请求/响应格式:JSON
- 成功响应码:200
请求体字段
| 字段名 | 类型 | 必填 | 说明 |
|---|---|---|---|
file | string | 是 | 图像或 PDF 文件的 URL,或 Base64 编码内容 |
fileType | int | 否 | 文件类型:0‑PDF,1‑图像。默认根据 URL 推断 |
useDocOrientationClassify | boolean | 否 | 是否启用文档方向分类 |
useDocUnwarping | boolean | 否 | 是否启用文档展平 |
useLayoutDetection | boolean | 否 | 是否启用版面检测 |
useChartRecognition | boolean | 否 | 是否启用图表识别 |
layoutThreshold | number/object | 否 | 版面检测阈值 |
layoutNms | boolean | 否 | 是否启用 NMS |
layoutUnclipRatio | number/array/object | 否 | 检测框扩展比例 |
layoutMergeBboxesMode | string/object | 否 | 检测框合并模式 |
promptLabel | string | 否 | 提示标签 |
formatBlockContent | boolean | 否 | 是否格式化块内容 |
repetitionPenalty | number | 否 | 重复惩罚系数 |
temperature | number | 否 | 采样温度 |
topP | number | 否 | 核心采样参数 |
minPixels | number | 否 | 最小像素数 |
maxPixels | number | 否 | 最大像素数 |
prettifyMarkdown | boolean | 否 | 是否美化 Markdown 输出(默认 true) |
showFormulaNumber | boolean | 否 | 是否显示公式编号(默认 false) |
visualize | boolean | 否 | 是否返回可视化图像(默认遵循配置文件) |
成功响应结构
{
"logId": "请求UUID",
"errorCode": 0,
"errorMsg": "Success",
"result": {
"layoutParsingResults": [
{
"prunedResult": { /* 简化后的版面解析结果 */ },
"markdown": {
"text": "Markdown文本",
"images": { "图片路径": "Base64图片" },
"isStart": true,
"isEnd": false
},
"outputImages": { /* 可视化图像(Base64)*/ },
"inputImage": "Base64原始图像"
}
],
"dataInfo": { /* 输入数据信息 */ }
}
}9.6.2 多语言调用示例
Python 示例
import base64
import requests
import pathlib
API_URL = "http://localhost:8080/layout-parsing"
image_path = "./demo.jpg"
with open(image_path, "rb") as file:
image_data = base64.b64encode(file.read()).decode("ascii")
payload = {
"file": image_data,
"fileType": 1,
}
response = requests.post(API_URL, json=payload)
assert response.status_code == 200
result = response.json()["result"]
# 处理结果
for i, res in enumerate(result["layoutParsingResults"]):
print(res["prunedResult"])
# 保存 Markdown
md_dir = pathlib.Path(f"markdown_{i}")
md_dir.mkdir(exist_ok=True)
(md_dir / "doc.md").write_text(res["markdown"]["text"])
# 保存图片
for img_path, img in res["markdown"]["images"].items():
(md_dir / img_path).write_bytes(base64.b64decode(img))其他语言(C++、Java、Go、C#、Node.js)的调用示例可参考官方文档或根据上述 Python 示例进行相应实现。
在线API参考:https://ai.baidu.com/ai-doc/AISTUDIO/2mh4okm66
9.7 离线部署说明
若需要在无网络环境中部署,可执行以下步骤:
在联网机器上拉取所需镜像:
bashdocker compose pull导出镜像包:
bashdocker save -o paddleocr-images.tar $(docker images | grep paddleocr | awk '{print $1":"$2}')将镜像包传输至离线机器并导入:
bashdocker load -i paddleocr-images.tar在离线环境中执行
docker compose up启动服务。
十、常见问题与解决方案
10.1 GPU 内存不足(如 RTX 5060 8G)
ERROR 12-01 02:12:09 [core.py:718] ValueError: Free memory on device (6.77/7.96 GiB) on startup is less than desired GPU memory utilization (0.99, 7.88 GiB). Decrease GPU memory utilization or reduce GPU memory used by other processes.调整 gpu-memory-utilization 和 max-num-batched-tokens 参数,降低显存占用:
paddleocr genai_server --model_name PaddleOCR-VL-0.9B --host 0.0.0.0 --port 8118 --backend vllm --backend_config <(echo -e 'gpu-memory-utilization: 0.8\nmax-model-len: 7520\nmax-num-batched-tokens: 16384')10.2 Docker 服务连接失败(如 Windows)
curl: (28) Failed to connect to host.docker.internal port 8118 after 21032 ms: Could not connect to server若从宿主机无法访问服务,请按以下步骤排查:
在容器内测试服务:
bashdocker exec -it <container_id> curl http://localhost:8118/health若容器内正常,重启容器并映射端口:
bashdocker run -it --gpus all -p 8118:8118 --user root <image_id> /bin/bash在容器内启动服务后,再从宿主机测试。
检查防火墙与网络策略:确保宿主机防火墙未阻断 8118 端口。
10.3 容器停止后如何重新启动服务
如果容器已停止,但希望再次运行服务,可按以下步骤操作:
# 查看所有容器(包括已停止的)
docker ps -a
# 启动指定容器
docker start <容器ID或名称>
# 进入容器交互终端
docker exec -it <容器ID或名称> /bin/bash
# 在容器内启动 PaddleOCR-VL 服务
## 进入容器后,运行以下命令启动 vLLM 推理服务(可根据需要调整参数):
paddleocr genai_server --model_name PaddleOCR-VL-0.9B --host 0.0.0.0 --port 8118 --backend vllm --backend_config <(echo -e 'gpu-memory-utilization: 0.8\nmax-model-len: 7520\nmax-num-batched-tokens: 32768')
# 直接启动并进入容器(一键式)
## 若容器已存在但未运行,也可使用以下命令直接启动并进入交互终端:
docker start <容器ID> && docker exec -it <容器ID> /bin/bash十一、PaddleOCR-VL-0.9B SFT(有监督微调)
1. 引言
虽然 PaddleOCR-VL-0.9B 在常见场景下表现出色,但在许多特定或复杂的业务场景中,其性能会遇到瓶颈。例如:
- 特定行业与专业领域
- 金融与财会领域:识别发票、收据、银行对账单、财务报表等
- 医疗领域:识别病历、化验单、医生手写处方、药品说明书等
- 法律领域:识别合同、法律文书、法庭文件、证书等
- 非标准化的文本与字体
- 手写体识别:识别手写的表单、笔记、信件、问卷调查等
- 艺术字体与设计字体:识别海报、广告牌、产品包装、菜单上的艺术字体等
- 古籍与历史文献:识别古代手稿、旧报纸、历史档案等
- 特定任务与输出格式
- 表格识别与结构化输出:将图像中的表格转换为 Excel、CSV 或 JSON 格式
- 数学公式识别:识别教科书、论文中的数学公式,并输出为 LaTeX 等格式
这时,就需要通过 SFT (Supervised Fine-Tuning) 来提升模型的准确性和鲁棒性。
2. 环境配置
请确保在 CUDA12 以上的环境下,安装 ERNIE 与相关依赖,为了避免环境问题,我们推荐基于 Paddle 官方镜像构建容器。
2.1. 构建容器
镜像中已经包含了飞桨框架,无需额外安装。
docker run --gpus all --name erniekit-ft-paddleocr-vl -v $PWD:/paddle --shm-size=128g --network=host -it ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddle:3.2.0-gpu-cuda12.6-cudnn9.5 /bin/bash
# Windows
docker run --gpus all --name erniekit-ft-paddleocr-vl -v ${PWD}:/paddle --shm-size=128g --network=host -it ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddle:3.2.0-gpu-cuda12.6-cudnn9.5 /bin/bash2.2. 安装 ERNIEKit
拉取 ERNIEKit 并安装依赖:
git clone https://github.com/PaddlePaddle/ERNIE -b release/v1.4
cd ERNIE
python -m pip install -r requirements/gpu/requirements.txt
python -m pip install -e . # 以“可编辑”模式安装当前项目包
python -m pip install tensorboard
python -m pip install opencv-python-headless
python -m pip install numpy==1.26.4
# 如果下载较慢可尝试
python -m pip install -r requirements/gpu/requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
python -m pip install -e . # 以“可编辑”模式安装当前项目包
python -m pip install tensorboard -i https://mirrors.aliyun.com/pypi/simple/
python -m pip install opencv-python-headless -i https://mirrors.aliyun.com/pypi/simple/
python -m pip install numpy==1.26.4 -i https://mirrors.aliyun.com/pypi/simple/更多安装方式请参考 ERNIEKit-安装文档。
3. 模型和数据集准备
3.1. 模型准备
在 huggingface 或者 modelscope 可以下载 PaddleOCR-VL-0.9B 模型。
huggingface-cli download PaddlePaddle/PaddleOCR-VL --local-dir PaddlePaddle/PaddleOCR-VL
# 国内尝试
modelscope download --model PaddlePaddle/PaddleOCR-VL --local_dir ./PaddleOCR3.2. 数据集准备
训练所用的数据集格式,请参考 ERNIEKit - SFT VL Dataset Format 进行准备。数据样本中必需字段:
text_info:文本数据列表,其中每个元素包含一个text和一个tag。text:查询 Query 或回复 Response 的文本内容。tag:掩码标签(no_mask表示包含在训练中,对应 Response;mask表示从训练中排除,对应 Query)。
image_info:图像数据列表,其中每个元素包含一个image_url和一个matched_text_index。image_url:用于在线下载图像的 URL,或本地访问图像的路径。matched_text_index:在text_info中匹配文本的索引。- 默认值:
matched_text_index=0表示该图像与第一个文本匹配,并将被置于第一个文本之前。
- 默认值:
备注:
- 每个训练样本均为 JSON 格式,多个样本之间用换行符分隔。
- 请确保在
text_info中,带mask标签的项和带no_mask标签的项交替出现。
为了方便起见,我们也提供了一个快速上手的孟加拉语训练数据集,可用于微调 PaddleOCR-VL-0.9B 对孟加拉语进行识别,使用以下命令下载:
wget https://paddleformers.bj.bcebos.com/datasets/ocr_vl_sft-train_Bengali.jsonl孟加拉语训练数据示例:

{
"image_info": [
{"matched_text_index": 0, "image_url": "./assets/table_example.jps"},
],
"text_info": [
{"text": "OCR:", "tag": "mask"},
{"text": "দডর মথ বধ বকসট একনজর দখই চনত পরল তর অনমন\nঠক পনতই লকয রখছ\nর নচ থকই চচয বলল কশর, “এইই; পযছ! পযছ!'\nওপর", "tag": "no_mask"},
]
}表格/公式/图表数据会使用特殊的识别格式,细节请参考8.1. 表格/公式/图表数据格式
4. 训练配置
我们针对孟加拉语示例数据集提供了配置文件,其中的关键训练超参数如下:
max_steps=926:训练总步数, 约等于(D × E) / (G × B × A)。D=29605:数据集中训练样本数目。E=2:训练轮次数目。G=1:用于训练的 GPU 数目。B=8:单卡的训练 Batch Size。A=8:梯度累积步数。
warmup_steps=10:线性预热步数, 建议设置成最大步数的 1%0.01 × max_steps。packing_size=8:序列中打包的样本数目,作用等同于batch_size。max_seq_len=16384:最大序列长度,建议设置成训练过程中显存允许的最大值。gradient_accumulation_steps=8:梯度累积步数。- 每达到该步数整数倍更新一次模型参数。
- 当显存不足时,可以减小
packing_size并增大gradient_accumulation_steps。 - 用时间换空间策略,可以减少显存占用,但会延长训练时间。
learning_rate=5e-6:学习率,即每次参数更新的幅度。
5. SFT 训练
使用以下命令行即可启动训练:
CUDA_VISIBLE_DEVICES=0 \
erniekit train examples/configs/PaddleOCR-VL/sft/run_ocr_vl_sft_16k.yaml \
model_name_or_path=PaddlePaddle/PaddleOCR-VL \
train_dataset_path=./ocr_vl_sft-train_Bengali.jsonl \在 1*A800-80 G 上训练时长约为 2 小时。
ERNIEKit 默认使用机器上的全部 GPU,可以通过环境变量 CUDA_VISIBLE_DEVICES 设置 ERNIEKit 能够使用的 GPU。
GPU 的数目 GPU_num 会影响训练超参数 learning_rate & packing_size & gradient_accumulation_steps 配置。理论上,每个更新步使用的样本数目 sample_num = G*B*A,近似与学习率 learning_rate 成正线形关系,因此,当 GPU 数目增加 N 倍变为 N*GPU 时,有两种调整方式:
- 保持
sample_num不变- 将
packing_size减少x倍,变成packing_size/x - 将
gradient_accumulation_steps减少y倍,变成gradient_accumulation_steps/y - 满足
x*y = N即可
- 将
- 将
learning_rate增加N倍,变成N*learning_rate
可以通过 tensorboard 对训练过程可视化,使用以下命令行即可启动(下方命令将端口 port 设置为 8084,需要根据实际情况设置可用端口):
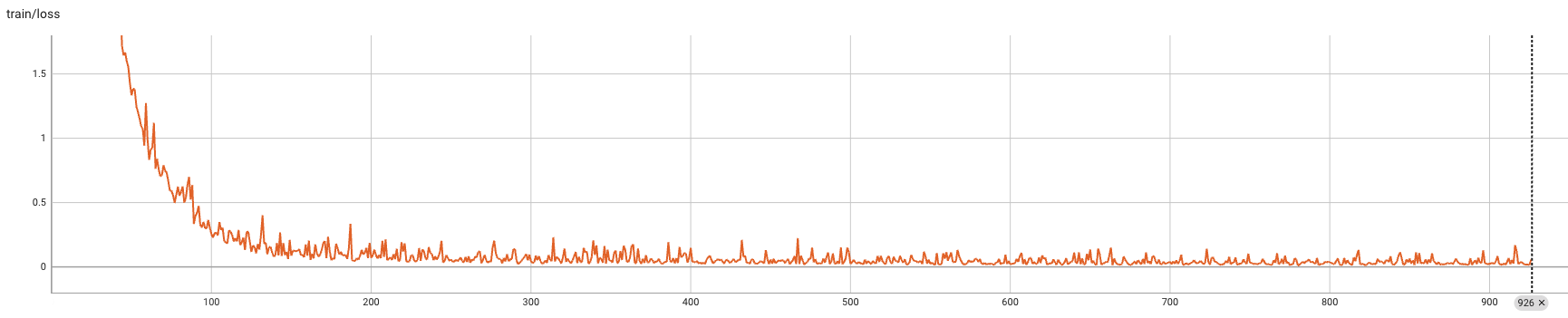
tensorboard --logdir ./PaddleOCR-VL-SFT-Bengali/tensorboard_logs/ --port 8084成功启动后该服务后,在浏览器输入 ip:port ,则可以看到训练日志(通过 hostname -i 命令可以查看机器的 ip 地址)。
损失曲线如下:
6. 模型结构说明
训练结束后,模型会保存在 output_dir=./PaddleOCR-VL-SFT-Bengali 指定路径下,其中包含:
- preprocessor_config.json:图像预处理配置文件
- config.json:模型配置文件
- model-00001-of-00001.safetensors:模型权重文件
- 保存的模型格式可以通过
save_to_hf控制,默认是 huggingface safetensors 格式
- 保存的模型格式可以通过
- model.safetensors.index.json & static_name_to_dyg_name.json:模型权重索引文件等,用于辅助模型在多 GPU 上切分与加载
- tokenizer.model & tokenizer_config.json & special_tokens_map.json & added_tokens.json:分词器文件
- train_args.bin:训练参数文件,记录训练使用的参数等
- train_state.json:训练状态文件,记录训练步数和最优指标等
- train_results.json & all_results.json:训练结果文件,记录训练进度&用时&每步耗时&每样本耗时等
- generation.json:生成配置文件
- checkpoint-[save_steps*n]:检查点文件夹,在
save_steps整数倍保存训练状态,除以上文件外,还会保存 master-weight & optimizer-state & scheduler-state 等,可用于训练中断后恢复训练
7. 推理
7.1. 推理环境配置
安装 PaddleOCR 用于推理
python -m pip install -U "paddleocr[doc-parser]"
python -m pip install https://paddle-whl.bj.bcebos.com/nightly/cu126/safetensors/safetensors-0.6.2.dev0-cp38-abi3-linux_x86_64.whl
python -m pip install --force-reinstall opencv-python-headless
python -m pip install numpy==1.26.47.2. 推理模型准备
从 PaddleOCR-VL 中拷贝必要的推理配置文件到 SFT 训练完成后保存的模型目录中
cp PaddlePaddle/PaddleOCR-VL/chat_template.jinja PaddleOCR-VL-SFT-Bengali
cp PaddlePaddle/PaddleOCR-VL/inference.yml PaddleOCR-VL-SFT-Bengali7.3. 推理数据集准备
我们提供了孟加拉语测试数据集,可用于推理来观察微调效果,使用以下命令下载:
wget https://paddleformers.bj.bcebos.com/datasets/ocr_vl_sft-test_Bengali.jsonl7.4. 单样本推理
孟加拉语测试图像:

使用以下命令进行单样本推理:
paddleocr doc_parser -i https://paddle-model-ecology.bj.bcebos.com/PPOCRVL/dataset/bengali_sft/5b/7a/5b7a5c1c-207a-4924-b5f3-82890dc7b94a.png \
--vl_rec_model_name "PaddleOCR-VL-0.9B" \
--vl_rec_model_dir "./PaddleOCR-VL-SFT-Bengali" \
--save_path="./PaddleOCR-VL-SFT-Bengali_response"
# GT = নট চলল রফযনর পঠ সওযর\nহয গলয গলয ভব এখন দটত, মঝ মঝ খবর নয যদও লগ যয\nঝগড\nদরগর কছ চল এল
# Excepted Answer = নট চলল রফযনর পঠ সওযর\nহয গলয গলয ভব এখন দটত, মঝ মঝ খবর নয যদও লগ যয\nঝগড\nদরগর কছ চল এল上述命令会在 PaddleOCR-VL-SFT-Bengali_response 目录下保存结果和可视化图片,其中预测结果保存在以 .md 结尾的文件中。更多关于paddleocr工具的推理能力,请参考:https://www.paddleocr.ai/latest/version3.x/pipeline_usage/PaddleOCR-VL.html。
8. 注意事项
8.1. 表格/公式/图表数据格式
特别地,表格/公式/图表数据使用特殊的识别格式:
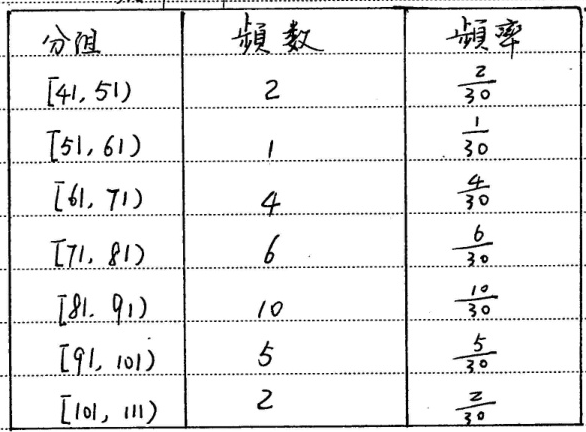
表格数据:OTSL 格式
{
"image_info": [
{"matched_text_index": 0, "image_url": "./assets/table_example.jps"},
],
"text_info": [
{"text": "Table Recognition:", "tag": "mask"},
{"text": "<fcel>分组<fcel>频数<fcel>频率<nl><fcel>[41,51)<fcel>2<fcel>\\( \\frac{2}{30} \\)<nl><fcel>[51,61)<fcel>1<fcel>\\( \\frac{1}{30} \\)<nl><fcel>[61,71)<fcel>4<fcel>\\( \\frac{4}{30} \\)<nl><fcel>[71,81)<fcel>6<fcel>\\( \\frac{6}{30} \\)<nl><fcel>[81,91)<fcel>10<fcel>\\( \\frac{10}{30} \\)<nl><fcel>[91,101)<fcel>5<fcel>\\( \\frac{5}{30} \\)<nl><fcel>[101,111)<fcel>2<fcel>\\( \\frac{2}{30} \\)<nl>", "tag": "no_mask"},
]
}公式数据: Latex格式
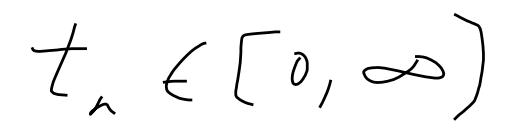
{
"image_info": [
{"matched_text_index": 0, "image_url": "./assets/formula_example.jps"},
],
"text_info": [
{"text": "Formula Recognition:", "tag": "mask"},
{"text": "\\[t_{n}\\in[0,\\infty]\\]", "tag": "no_mask"},
]
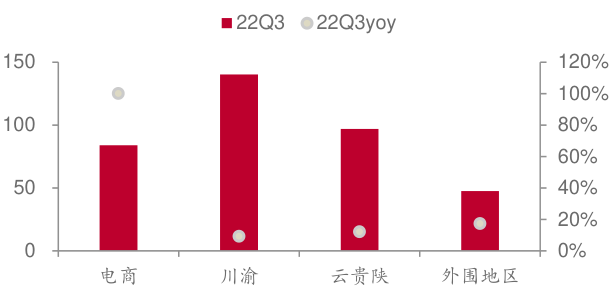
}图表数据:Markdown格式
{
"image_info": [
{"matched_text_index": 0, "image_url": "./assets/chart_example.png"},
],
"text_info": [
{"text": "Chart Recognition:", "tag": "mask"},
{"text": " | 22Q3 | 22Q3yoy\n电商 | 85 | 100%\n川渝 | 140 | 8%\n云贵陕 | 95 | 12%\n外围地区 | 45 | 20%", "tag": "no_mask"},
]
}常见问题
如果你使用上述命令过程中遇到下面的问题,一般是因为cv2和环境的冲突,可以通过安装 opencv-python-headless 来解决问题
问题表现
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.10/dist-packages/cv2/__init__.py", line 181, in <module>
bootstrap()
File "/usr/local/lib/python3.10/dist-packages/cv2/__init__.py", line 153, in bootstrap
native_module = importlib.import_module("cv2")
File "/usr/lib/python3.10/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
ImportError: libGL.so.1: cannot open shared object file: No such file or directory解决方案
python -m pip install --force-reinstall opencv-python-headless
python -m pip install numpy==1.26.4